Basic DL Using Pytorch
Pytorch
-
使用Pytorch 搭建简单的学习框架
-
理解简单的神经网络与深度学习概念
-
Tensor
-
基本数据类:包含
- data: 参数值
- grad: 参数偏导
-
.data 返回的仍然是Tensor
-
.item 返回的时标量
-
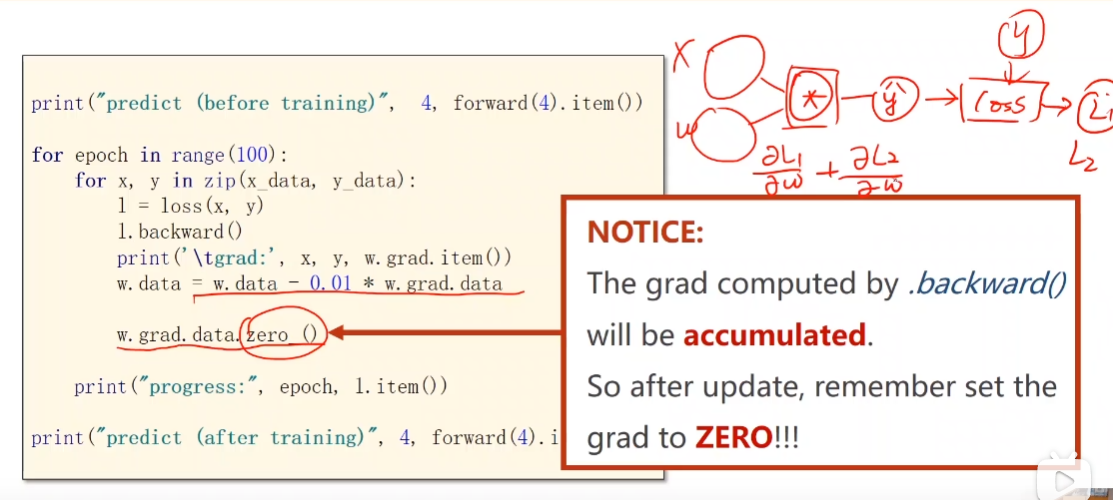
参数的梯度在每次反向传播之前需要清零,防止梯度累积
-
-
torch.nn.Liner(in,out):线性层:
- 输入:n*in_features_num
- 输出:n*out_features_num
-
torch.max(input,dim)
-
return:(最大值结果,最大值在规定维度下标)
-
dim
- 0:沿着最外层方向压缩:例如二维沿着行压缩,找出每列的最大值及下标
- 1:沿着次外层压缩:例如二维沿着列压缩,找出每行最大值及下标
-
-
步骤为:
- 先计算loss
- 再反向传播
- 梯度清零
-
import matplotlib.pyplot as plt import torch a = [1,2,3] b = [2,4,6] w = torch.rand(3) w.requires_grad_(True) # w = torch.rand(1) # w.requires_grad_(True) def forward(x) -> torch.Tensor: # return x * w x_feature = torch.Tensor([x,pow(x,2),1]) out = w.dot(x_feature) return(out) def loss(x,y) -> torch.Tensor: y_pred = forward(x) lose = pow(y_pred - y,2) return lose x = torch.Tensor([1.0,2.0,3.0]) y = torch.Tensor([2.0,3.0,5.0]) print(x.dot(y)) print("before traning, w = {} , pred = {} ".format(w.tolist(),forward(4))) times = 1000 learning_rate = 0.001 epoch_list = [] loss_list = [] for epoch in range(times): for x,y in zip(a,b): l = loss(x,y) l.backward() w.data = w.data - learning_rate * w.grad.data w.grad.data.zero_() print("number {} epoch, w = {} , loss = {} ".format(epoch,w.tolist(),l.item())) epoch_list.append(epoch) loss_list.append(l.item()) print("after traning, w = {} , pred = {} ".format(w.tolist(),forward(4))) plt.plot(epoch_list,loss_list) plt.show() # plt.plot(a,b) # plt.show()
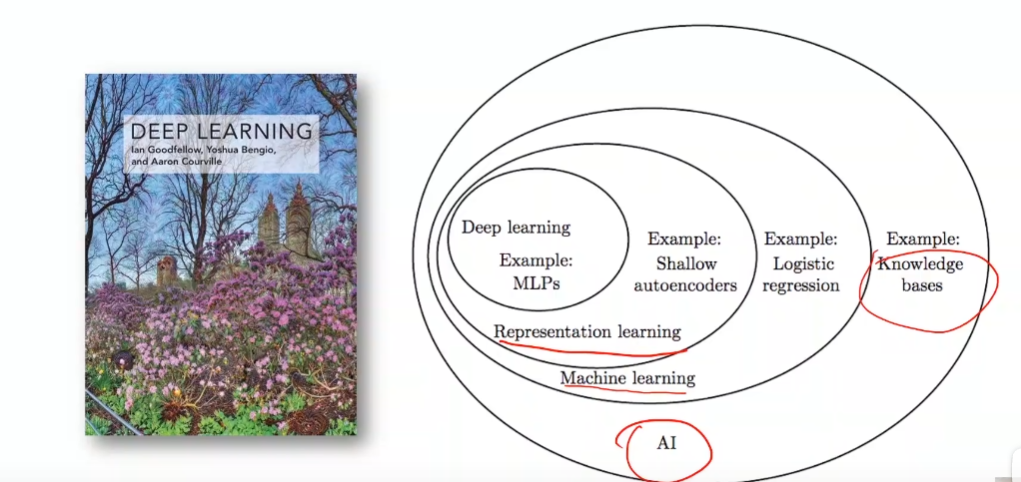
# Overview
- 分类
- 
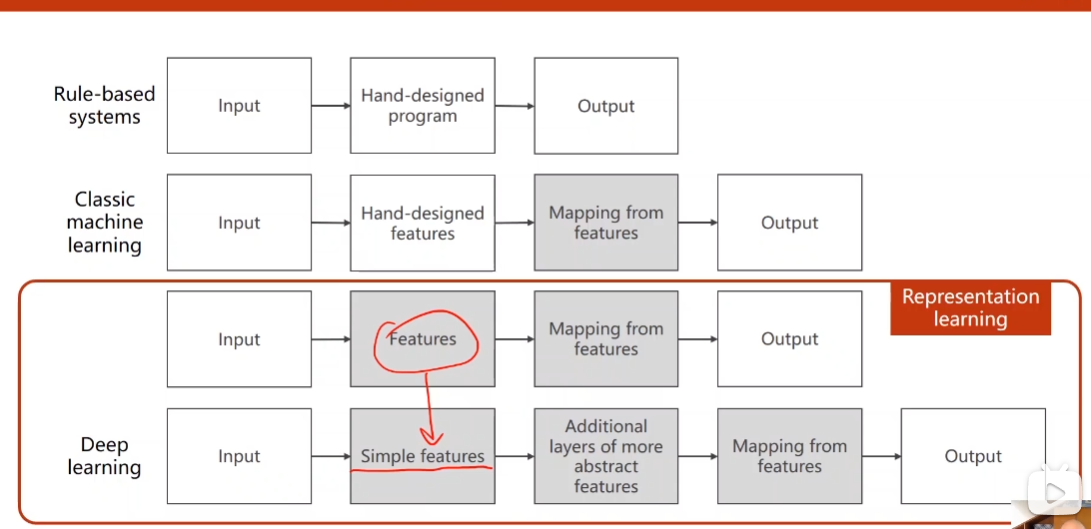
- 不同方法的比较
- 
# 线性模型
- MSE(Mean Square Error):样本平均损失误差
- Step
- 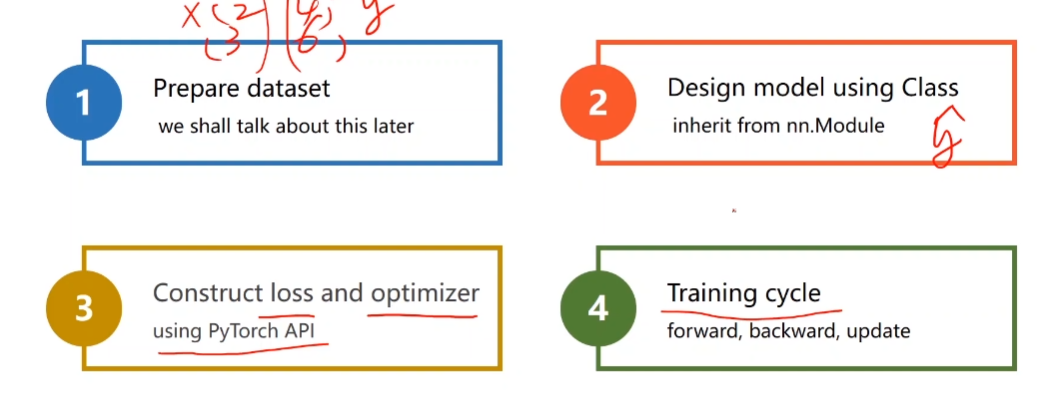
- 准备数据集
- 设计模型
- 使用pytorch 框架构造损失函数与 优化器
- 前向传播,反向传播,更新权重
- `torch.nn.Linear(in,out,bias=True)`
- 
- loss函数
- 
- 代码:
- ```python
import torch
import matplotlib.pyplot as plt
# prepared dataset
x = [[1.0],[2.0],[3.0]]
y = [[2.0],[4.0],[6.0]]
x_set = torch.Tensor(x)
y_set = torch.Tensor(y)
# Design the model use nn.model
class LinearModel(torch.nn.Module):
def __init__(self) -> None:
super().__init__()
self.liner = torch.nn.Linear(1,1)
def forward(self,x):
y_pred = self.liner(x)
return y_pred
model = LinearModel()
# construct loss and optimizer
lossfunc = torch.nn.MSELoss(reduction='mean')
# optmizer = torch.optim.SGD(model.parameters(),lr=0.01)
# optmizer = torch.optim.Adagrad(model.parameters(),lr=0.01)
# optmizer = torch.optim.Adam(model.parameters(),lr=0.01)
# optmizer = torch.optim.Adamax(model.parameters(),lr=0.01)
# optmizer = torch.optim.ASGD(model.parameters(),lr=0.01)
# optmizer = torch.optim.LBFGS(model.parameters(),lr=0.01)
# optmizer = torch.optim.RMSprop(model.parameters(),lr=0.01)
optmizer = torch.optim.Rprop(model.parameters(),lr=0.01)
## training cycle
epoch_list = []
loss_list = []
for epoch in range(1000):
y_pred = model(x_set)
loss = lossfunc(y_pred,y_set)
optmizer.zero_grad()
loss.backward()
optmizer.step()
for p in model.parameters():
print(" w = {} ".format(p.item()))
epoch_list.append(epoch)
loss_list.append(loss.item())
# plt.ion()
plt.plot(epoch_list,loss_list)
# plt.pause(0.01)
print(" w = {}".format(model.liner.weight.item()))
print(" bias = {}".format(model.liner.bias.item()))
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print("predict = {} ".format(y_test.item()))
# plt.ioff()
plt.show()
print
-
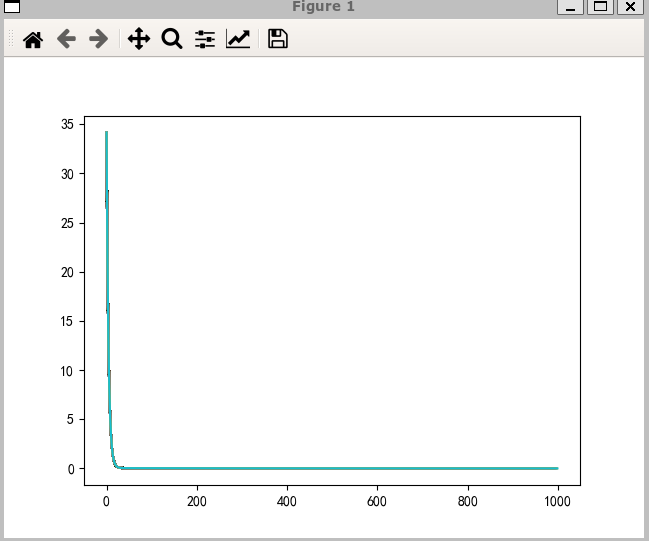
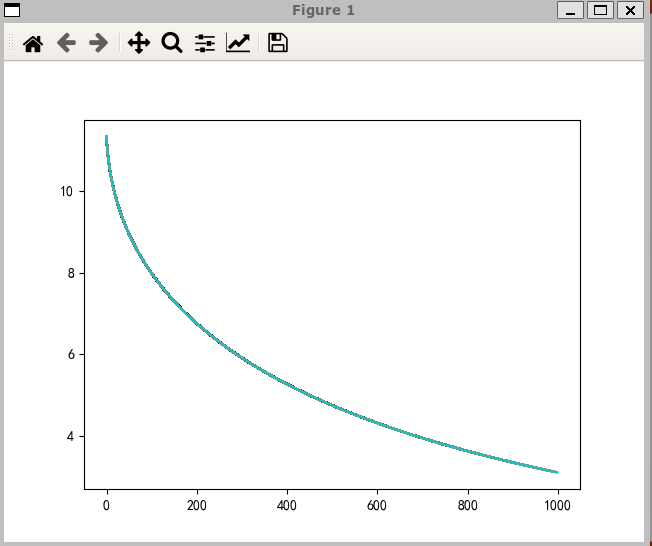
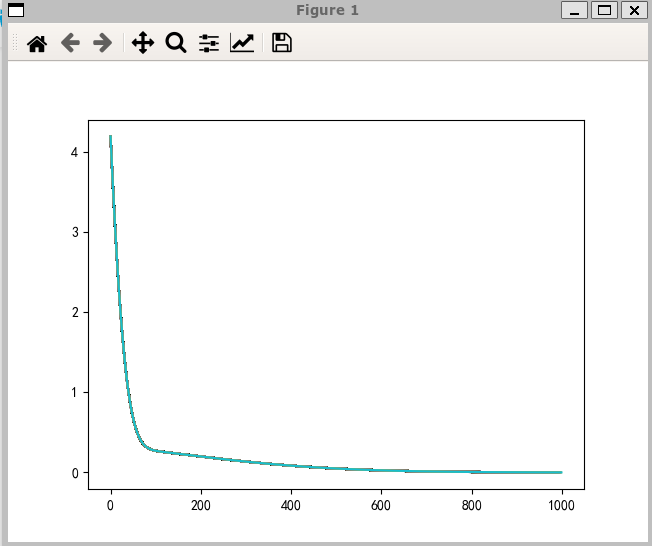
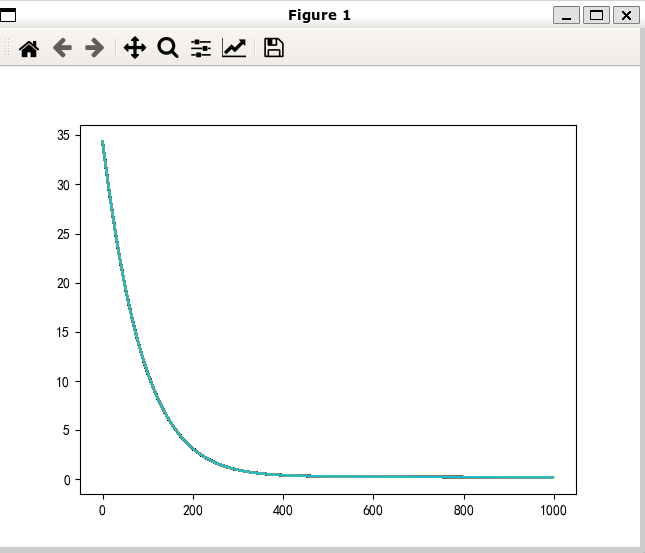
不同优化器图像
- SGD:
- SGD:
-
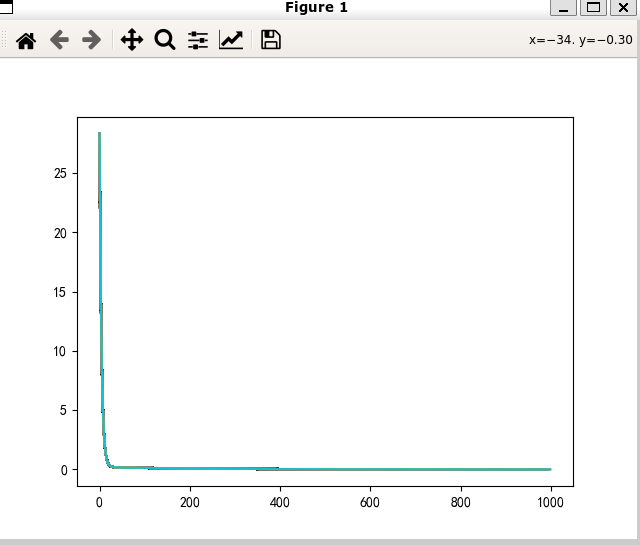
Adagrad
-
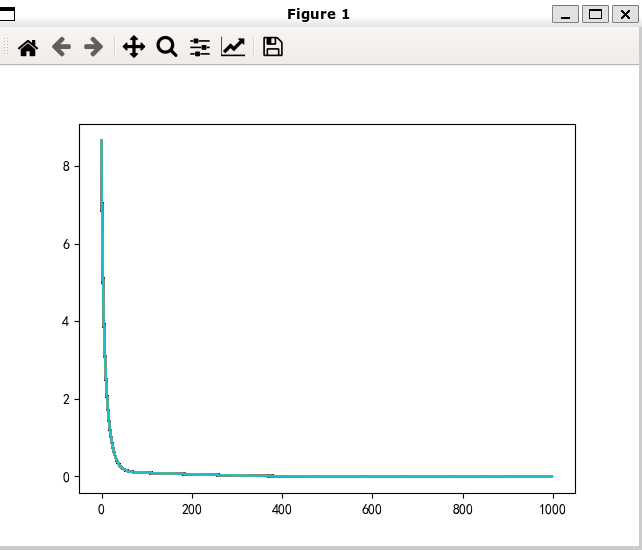
Adam
-
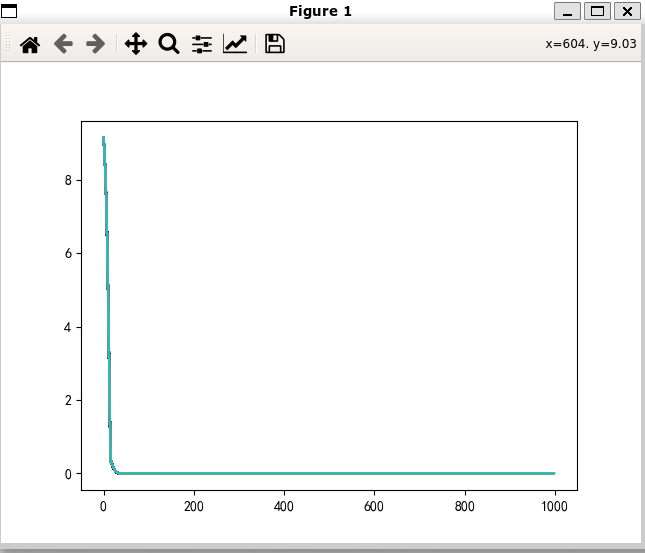
Adamax
-
ASGD
-
LBFGS
-
RMSprop
-
Rprop
逻辑回归
-
采用MSELoss 交叉损失函数,二分类
-
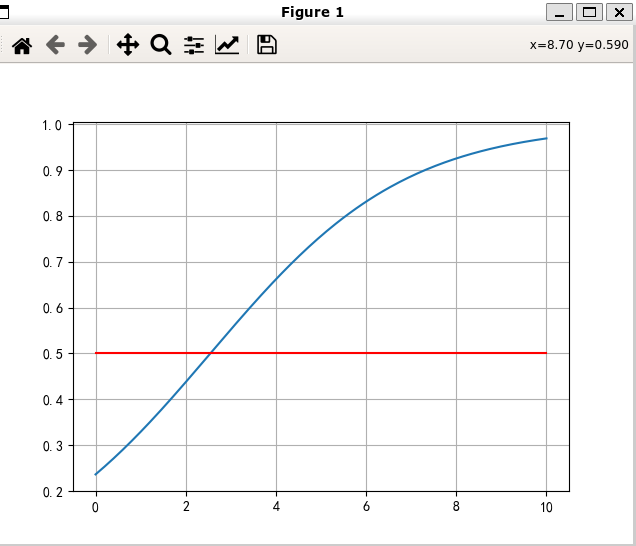
import matplotlib.pyplot as plt import numpy import torch # prepared dataset x = [[1.0],[2.0],[3.0]] y = [[0.0],[0.0],[1.0]] x_set = torch.Tensor(x) y_set = torch.Tensor(y) # design model class LogisticModel(torch.nn.Module): def __init__(self) -> None: super().__init__() self.liner = torch.nn.Linear(1,1) def forward(self,x): y = self.liner(x) y_pred = torch.sigmoid(y) return y_pred #construct lossfunc and optimizer logisticmodel = LogisticModel() lossfunc = torch.nn.BCELoss(reduction='mean') optimizer = torch.optim.SGD(logisticmodel.parameters(),lr=0.01) # training cycle for epoch in range(500): y_pred = logisticmodel(x_set) loss = lossfunc(y_pred,y_set) optimizer.zero_grad() loss.backward() optimizer.step() print("epoch = {} , loss = {}".format(epoch,loss.item())) print(" w = {}".format(logisticmodel.liner.weight.data)) print(" bias = {}".format(logisticmodel.liner.bias.data)) x = numpy.linspace(0,10,200).reshape(200,1) x_test = torch.Tensor(x) y_test = torch.Tensor(logisticmodel(x_test)) y = y_test.data.numpy() plt.plot(x,y) plt.plot([0,10],[0.5,0.5],c='r') plt.grid() plt.show()
- 预测图:
- 
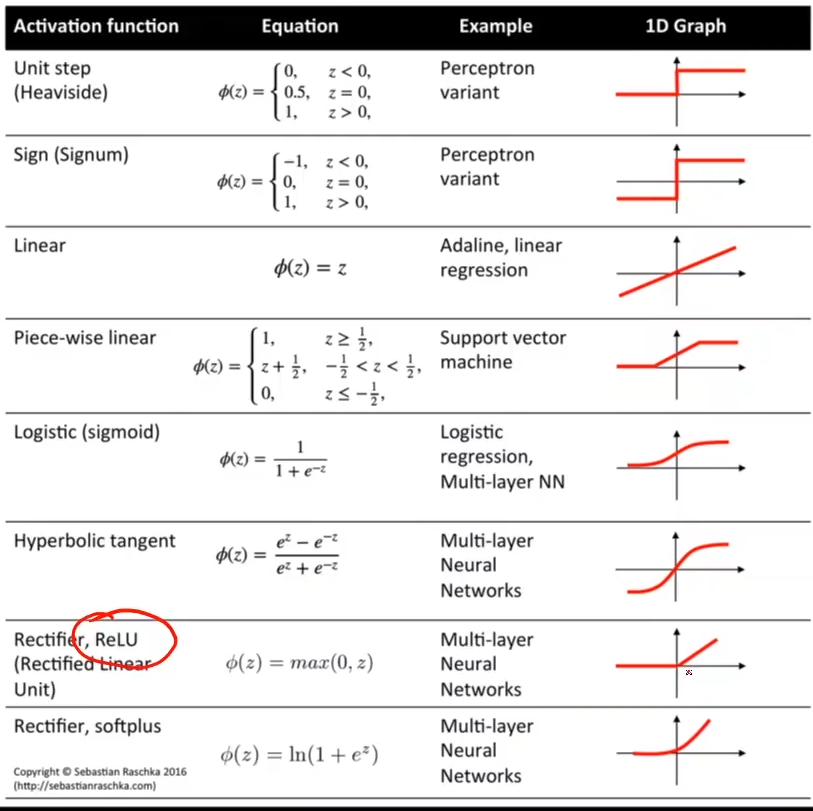
# 多维度
- 不同的激活函数:
- 
- Mini-Batch 中的概念
- epoch:每个epoch内所有样本进行一次前向传播与反向传播
- Batch-size:mini-batch大小
- iteration:每次epoch 迭代使用mini-batch的次数
## sklearn 中breast_cancer数据集做全连接预测
```python
from turtle import forward
import sklearn.datasets as ds
import numpy as np
import torch
diatbets = ds.load_breast_cancer()
# print(diatbets)
# exit()
normalizationer = torch.nn.BatchNorm1d(num_features=30)
train_set_num = int(len(diatbets.data)*0.6)
valiate_set_num = int(len(diatbets.data) * 0.2)
test_set_num = len(diatbets.data) - train_set_num - valiate_set_num
train_set_x = torch.Tensor(diatbets.data[:train_set_num+1])
valiate_set_x = torch.Tensor(diatbets.data[train_set_num+1:train_set_num+valiate_set_num+1])
test_set_x = torch.Tensor(diatbets.data[train_set_num+valiate_set_num+1:])
print("train_set shape = {} ".format(train_set_x.shape))
print("valiate_set shape = {}".format(valiate_set_x.shape))
print("test_set.shape = {}".format(test_set_x.shape))
train_set_y = torch.Tensor(diatbets.target[:train_set_num+1]).view(-1,1)
valiate_set_y = torch.Tensor(diatbets.target[train_set_num+1:train_set_num+valiate_set_num+1]).view(-1,1)
test_set_y = torch.Tensor(diatbets.target[train_set_num+valiate_set_num+1:]).view(-1,1)
# print(diatbets.target)
print('--------------------------')
print("train_set shape = {} ".format(train_set_y.shape))
print("valiate_set shape = {}".format(valiate_set_y.shape))
print("test_set.shape = {}".format(test_set_y.shape))
# exit()
class MutiDimensionModel(torch.nn.Module):
def __init__(self) -> None:
super().__init__()
self.liner1 = torch.nn.Linear(30,25)
self.liner2 = torch.nn.Linear(25,20)
self.liner3 = torch.nn.Linear(20,15)
self.liner4 = torch.nn.Linear(15,10)
self.liner5 = torch.nn.Linear(10,5)
self.liner6 = torch.nn.Linear(5,1)
self.sigmoid = torch.nn.Sigmoid()
self.relu = torch.nn.ReLU()
def forward(self,x):
a2 = self.relu(self.liner1(x)) # n * 25
a3 = self.relu(self.liner2(a2)) # n * 20
a4 = self.relu(self.liner3(a3))
a5 = self.sigmoid(self.liner4(a4))
a6 = self.sigmoid(self.liner5(a5))
a7 = self.sigmoid(self.liner6(a6))
return a7
mutidimensionmodule = MutiDimensionModel()
lossfunc = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(mutidimensionmodule.parameters(),lr=0.05,weight_decay=0.001)
for epoch in range(10000):
output = mutidimensionmodule(train_set_x)
loss = lossfunc(output,train_set_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if(epoch % 1000 == 0):
print("epoch = {} , loss = {} ".format(epoch,loss.item()))
test_output = mutidimensionmodule(test_set_x)
test_y = test_output.tolist()
test_set_lable = test_set_y.tolist()
all_num = len(test_y)
# print(test_y)
correct_num = 0
threshold = 0.5
for sample in range(all_num):
if(test_y[sample][0] > threshold):
predict = 1.0
else:
predict = 0.0
# print("predict = {}".format(predict))
# print("lable = {}".format(test_set_lable[sample][0]))
if(predict == test_set_lable[sample][0]):
correct_num = correct_num + 1;
print(correct_num)
print("accu = {}".format( correct_num / all_num) )
-
构造Dataset 与 Dataloader 用于做Mini-Bactch
-
Windows下dataloader 会出错:windows使用spawn做多进程,linux使用fork
-
实现DataSet(抽象类),三个方法
-
__init__(self) -
__getitem__(self,index) -
__len__(self) -
example:
-
class MyDataSet(Dataset): def __init__(self,data_x:torch.Tensor,data_y:torch.Tensor) -> None: super().__init__() self.set_num = int(len(data_x.data)) self.set_x = data_x self.set_y = data_y def __getitem__(self, index: Any) : return (self.set_x[index],self.set_y[index]) def __len__(self): return self.set_num train_set = MyDataSet(train_set_x,train_set_y) valiate_set = MyDataSet(valiate_set_x,valiate_set_y) test_set = MyDataSet(test_set_x,test_set_y) train_loader = DataLoader(train_set,batch_size=10,shuffle=True,num_workers=2)
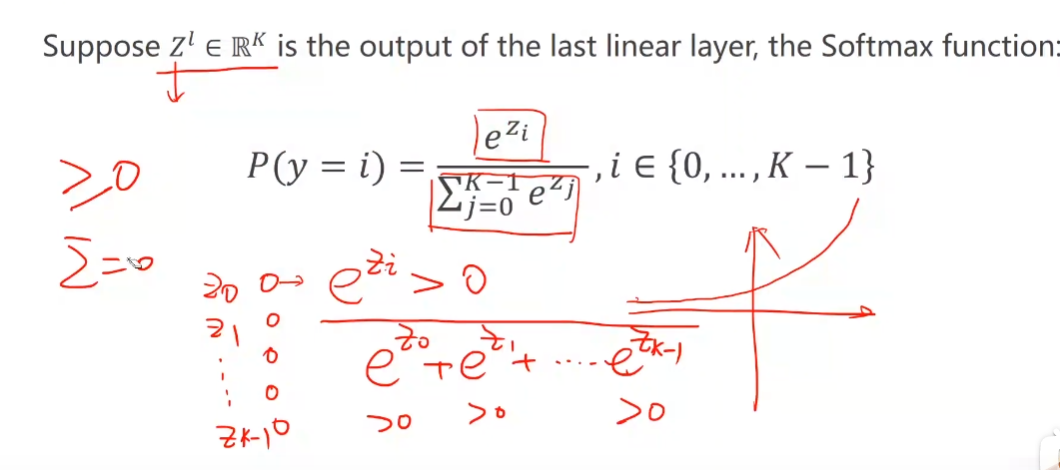
# 多分类
- softmax
- 用二分类做一对多多分类:多个二分类 分类器,输出为每一类得概率取最大值,因此拟合得模型输出得概率和可能不为1
- 
- 损失函数
- 关于交叉信息熵:
- 信息量:信息量的大小与信息发生的概率成反比。概率越大,信息量越小。概率越小,信息量越大。例如:太阳从东面出来,信息量为0,因为这是常识。再例如:2022世界杯中国队夺冠,信息量巨大啊,出啥问题了,其他队弃权了啊还是集体拉肚子了啊.......。
```latex
#公式表示: I(x)=−log(P(x))
-
-
信息熵:表示信息量的期望值。
#公式表示: H(X)=−∑P(xi)log(P(xi))) (X=x1,x2,x3...,xn)
-
相对熵(KL散度): 同一个随机变量X 有两个单独的概率分布P(x), Q(x),可以使用KL散度来衡量这两个概率分布之间的差异

展开:
-
展开发现前半部分是信息熵的公式,而在机器学习训练时候,样本的类别x和真实分布p(x)是已知的(已知标签值,即y的真实分布),那么信息熵就是个常数了。所以。后半部分就可以代表KL散度了。后半部分就叫交叉熵。
-
交叉熵: KL散度 = 交叉熵 + 信息熵。表面这个公式就是上面这个KL散度展开后,把后半截提取出 公式表示:
所以,想实现判定实际的输出分布与期望的输出分布的接近程度表述,就最小化交叉熵就好了
-
-
one-hot
- 一般的分类问题并不与类别之间的自然顺序有关。对此,我们使用一种简单的表示方法:独热编码(one-hot encoding)。独热编码是一个向量,它的分量和类别数目一样多,类别对应的分类设置为 1 ,其他所有分量设置为 0 。我们使用one hot编码器对类别进行“二进制化”操作,然后将其作为模型训练的特征。另外,如果原本的标签编码是有序的,那one hot编码就不合适了——会丢失顺序信息。
-
结合softmax,交叉熵,与one-hot编码,使用softmax的损失函数为
-
公式:
-
Y_i one-hot中为1的那一个
-
-
模型:

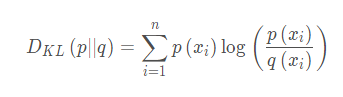
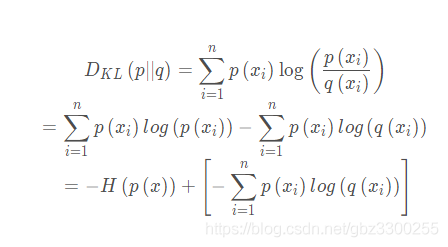
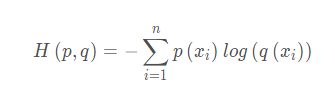
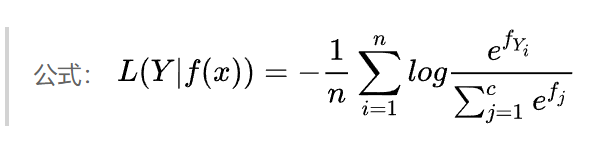
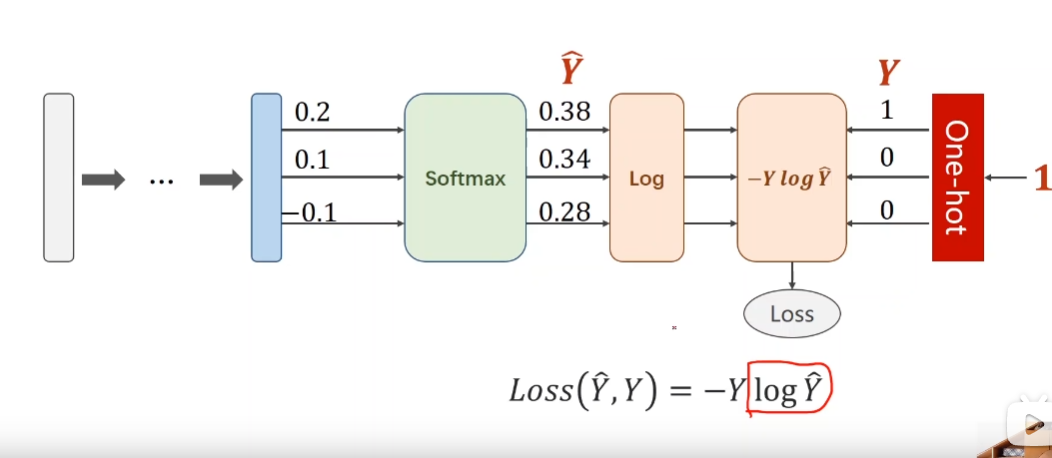
两个损失函数
-
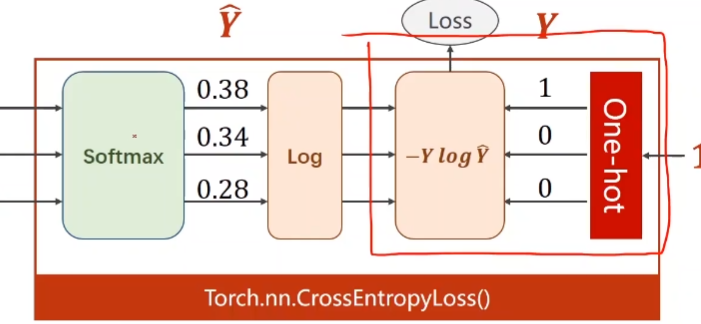
nn.CrossEntropyLoss
-
-
-
其中yi是one_hot标签,pi是softmax层的输出结果
-
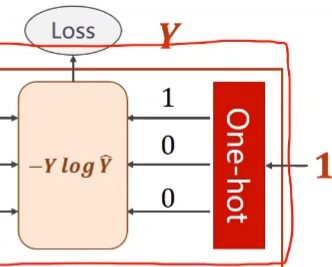
输入为无未经过softmax 激活的输出值,target为one-hot索引值或者one-hot编码
-
-
nn.NLLLoss():
Negative Log Liklihood(NLL) Loss:负对数似然损失函数:-
-
函数:
-
-
X是log_softmax()的输出,label是对应的标签位置
-
-
该函数的输入为经过了sofmax函数的计算与log计算的结果,target为one-hot索引值或one-hot编码
-
它不会为我们计算对数概率,适合最后一层是
log_softmax()(log_softmax也就是对softmax的输出取对数)的网络.
-
-
CrossEntropyLoss()=log_softmax() + NLLLoss()
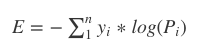
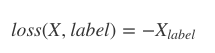
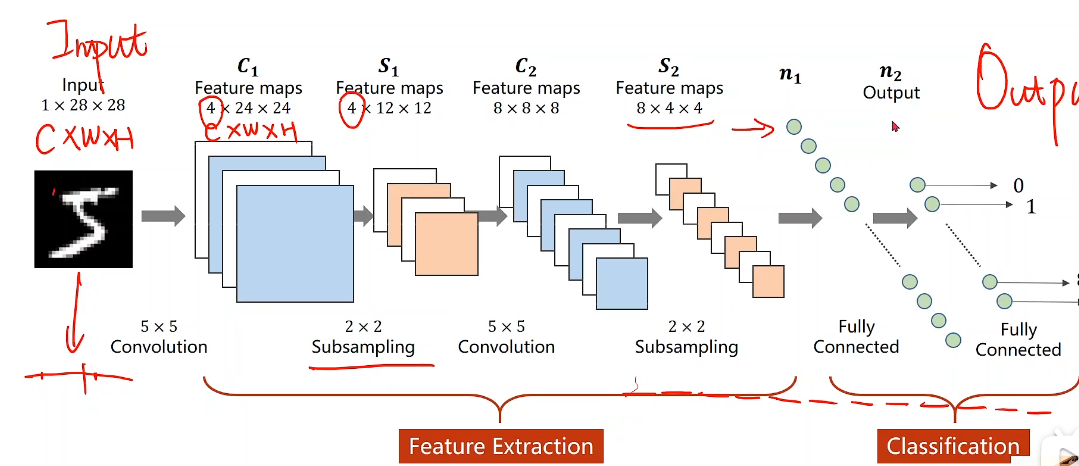
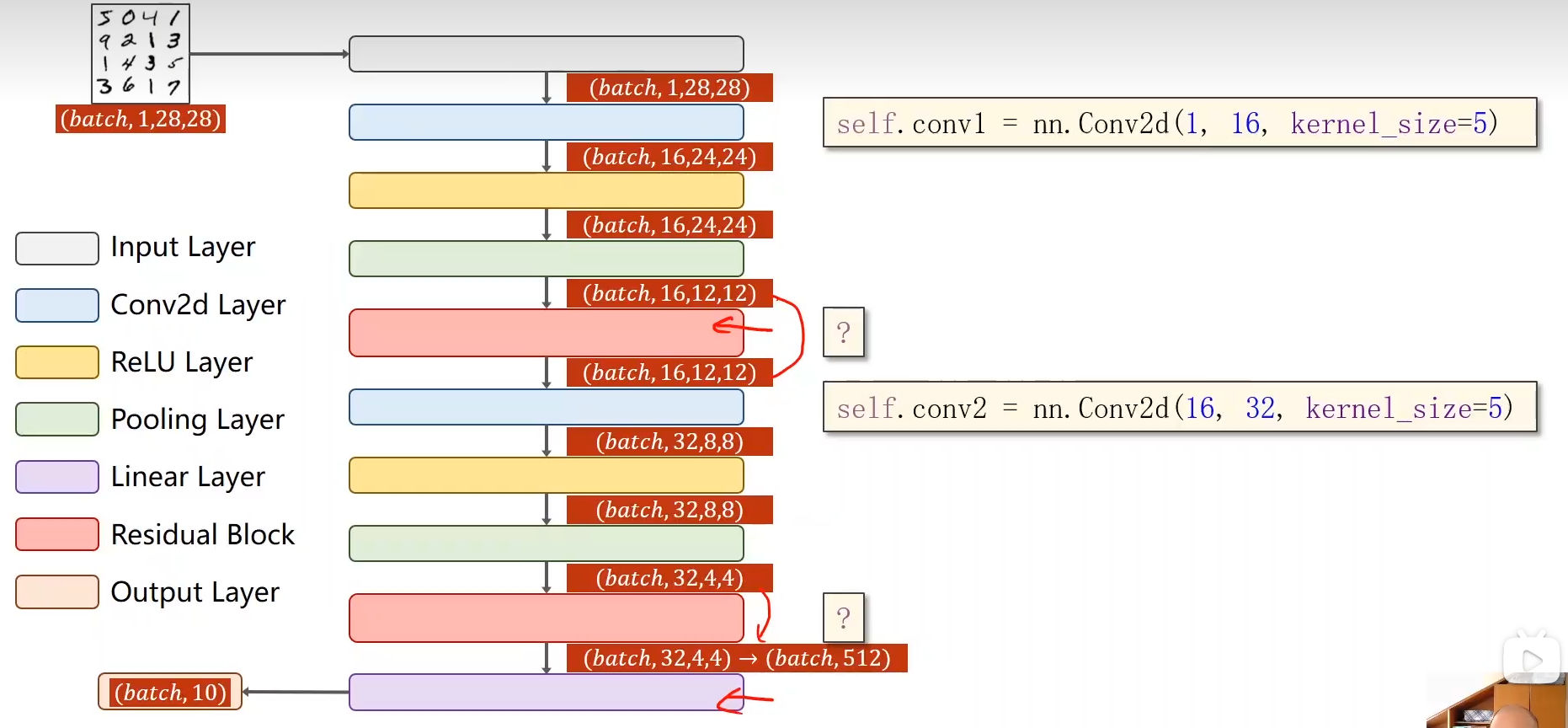
MNIST手写字符识别
全连接神经网络模型
-
图像:
- MNIST中; 28 * 28
-
通道:Channel
- 图象读取矩阵: W * H * C
- 转换为Tensor: C * W * H
-
通过
torchversion.transforms进行图像预处理:-
ToTensor():转换为C * W * H -
Normalzie(): 归一化:mean为0.1307,std为0.3081 -
transformers = transforms.Compose([ transforms.ToTensor(), # C * W * H transforms.Normalize((0.1307,),(0.3081,)) ])
- 读取MNIST数据集并制作 Dataloader 用于mini-batch
- ```python
train_set = datasets.MNIST(root='dataset/minist/',train=True,download=True,transform=transformers)
train_loader = DataLoader(train_set,shuffle=True,batch_size=batch_size,num_workers=4)
test_set = datasets.MNIST(root='dataset/minist/',train=True,download=True,transform=transformers)
test_loader = DataLoader(test_set,shuffle=True,batch_size=batch_size,num_workers=4)
-
-
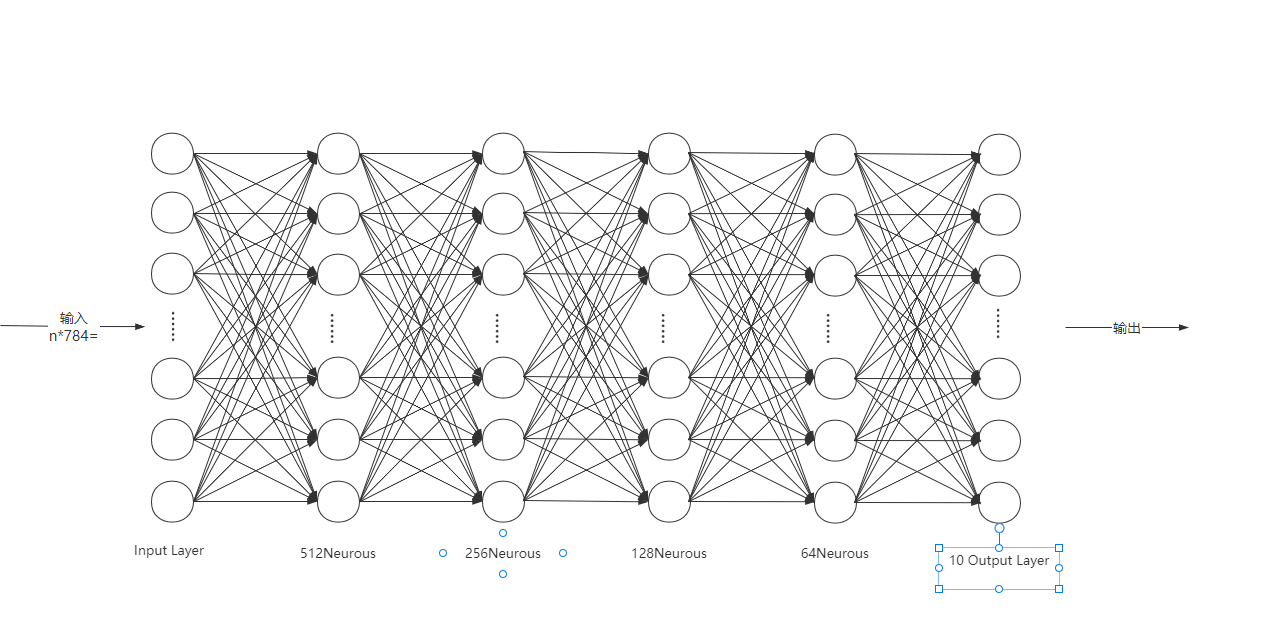
搭建全连接神经网络:
-
模型图:全连接层
-
将单通道图像数据扁平化为 1*784 向量输入数据
-
激活函数采用Relu做非线性处理
-
输出层不做softmax激活,采用
torch.nn.CrossEntropyLoss(*reduction*='mean')做softmax处理
-
-
训练模型:
-
def train(epoch): epoch_loss = 0.0 for index ,data in enumerate(train_loader,0): input,lables= data optimizer.zero_grad() output = model(input) loss = lossfunc(output,lables) loss.backward() optimizer.step() epoch_loss = epoch_loss + loss.item() if(index % 300 == 299): print('[ epoch = {} ,iteration = {} ] , loss = {}'.format(epoch,index,epoch_loss)) # epoch_loss = 0.0 if(epoch % 10 ==0 ): print('[ epoch = {} ] , loss = {}'.format(epoch,epoch_loss)) epoch_loss = 0.0
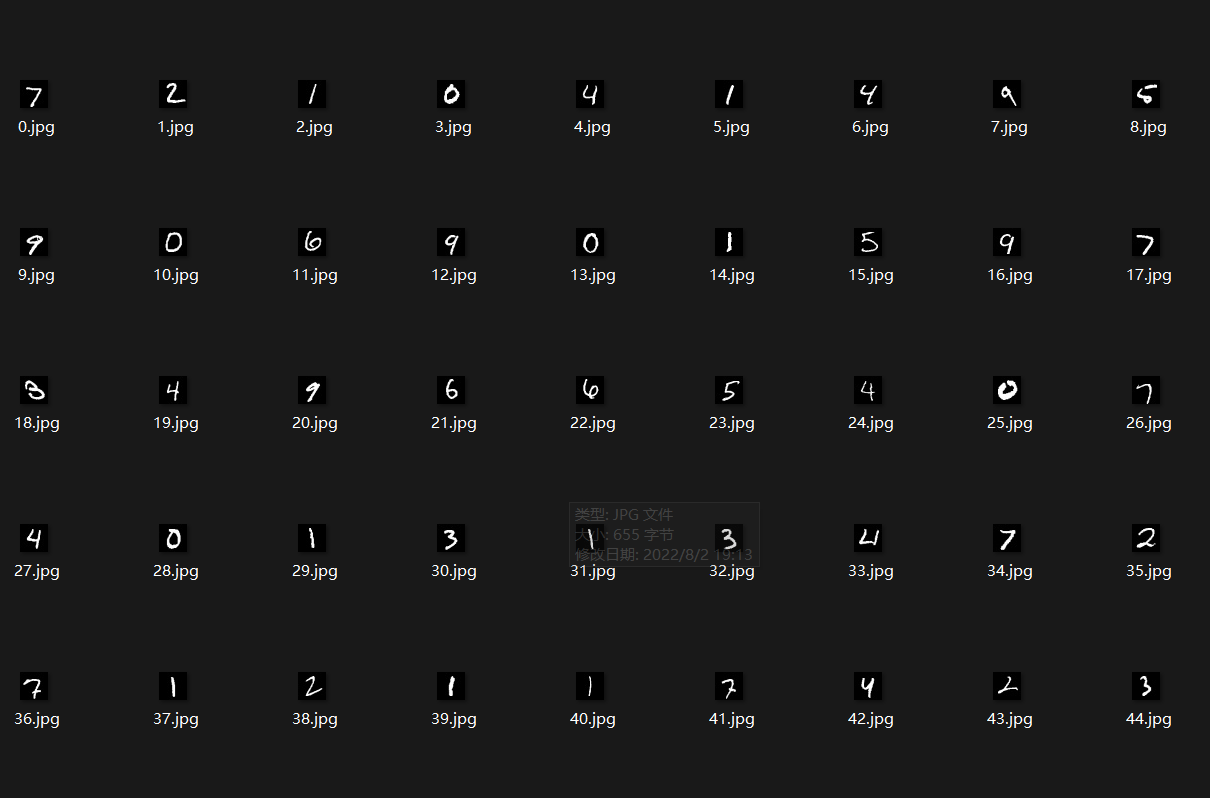
- 选用50张测试图片做可视化处理验证:
- 读取数据集bytes并转换为图片
- ```python
import cv2
import struct
test_image = 'dataset/minist/MNIST/raw/t10k-images-idx3-ubyte'
with open(test_image,'rb') as pic:
# magic_num = int.from_bytes(pic.read(4),byteorder='big',signed=False)
# num = int.from_bytes(pic.read(4),byteorder='big',signed=False)
# row = int.from_bytes(pic.read(4),byteorder='big',signed=False)
# col = int.from_bytes(pic.read(4),byteorder='big',signed=False)
# print("magic_num = {} , num = {}, row = {}, col = {}".format(magic_num,num,row,col))
magic_num = struct.unpack('>i',pic.read(4))
num = struct.unpack('>i',pic.read(4))
row = struct.unpack('>i',pic.read(4))
col = struct.unpack('>i',pic.read(4))
print("magic_num = {} , num = {}, row = {}, col = {}".format(magic_num,num,row,col))
for i in range(50):
image = []
for j in range(row[0] * col[0]):
# image.append(int.from_bytes(pic.read(1),byteorder='big',signed=False))
image.append(struct.unpack('>B',pic.read(1))[0])
image = np.array(image,dtype=np.uint8).reshape(row[0],col[0])
if not os.path.exists('mnist_images'):
os.mkdir('mnist_images')
cv2.imwrite('mnist_images/{}.jpg'.format(i),image) -
-
-
输入图片并输出结果列表
-
def test_pics(): image = [] for num in range(50): validate_img = cv.imread('image/{}.jpg'.format(num)) validate_img = cv.cvtColor(validate_img,cv.COLOR_RGB2GRAY) data = transformers(validate_img) image.append(data.tolist()) images = torch.Tensor(image) print(images.data.shape) output_t = model(images) _, pred_t = torch.max(output_t.data,dim=1) print(pred_t.tolist()) with open('res.txt','a+') as f: f.write(str(pred_t.tolist())) f.write("\n")
- 测试准确率
- ```python
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
input,lables= data
total = total + lables.size(0)
output = model(input)
_, pred = torch.max(output.data,dim=1)
correct = correct + (pred == lables).sum().item()
print('accu = {} % on test set '.format(100 * correct / total))
test_pics()
-
CNN Basic
-
网络结构
-
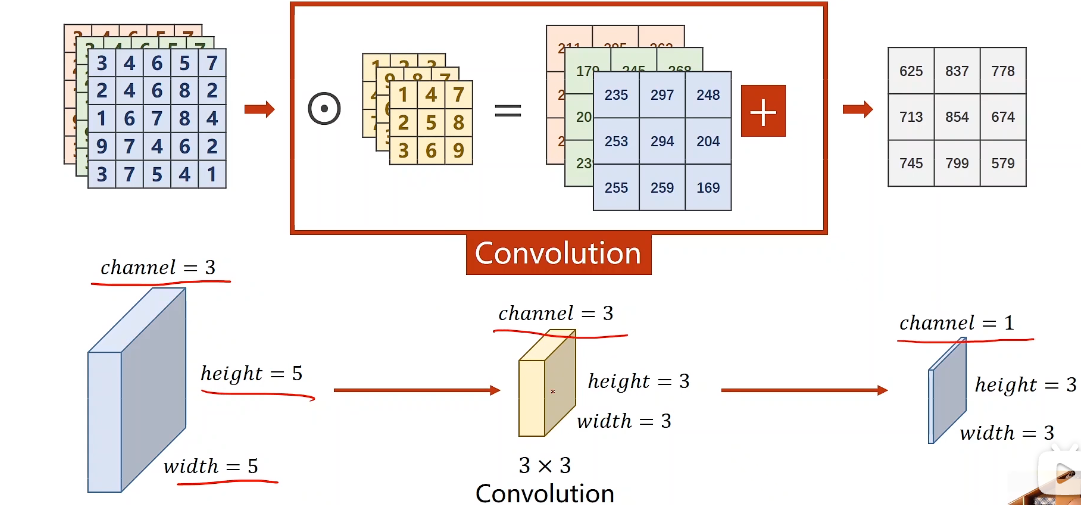
Convolution 卷积
-
形象化演示:
-
卷积核为什么能够提取到特征
- 如果有图片的局部区域跟filter矩阵比较相似,在进行卷积后的输出值会比较大。卷积值越大,就越表明检测到filter对应的物体特征。
- filter的大小只覆盖图片的局部区域,这种局部连接可以让特征只关注其应该关注的部分。这种设计符合人类对物体认知原理的,试想一下,我们在看到一只猫后,其实是记住这只猫各个区域最显著的特征,这样当我们看到一只狗时,就能够根据局部特征区分猫与狗。
- 同一个filter在进行卷积计算时参数是不变的,也被称作权值共享,这样就可以检测不同区域上相同的物体特征。
-
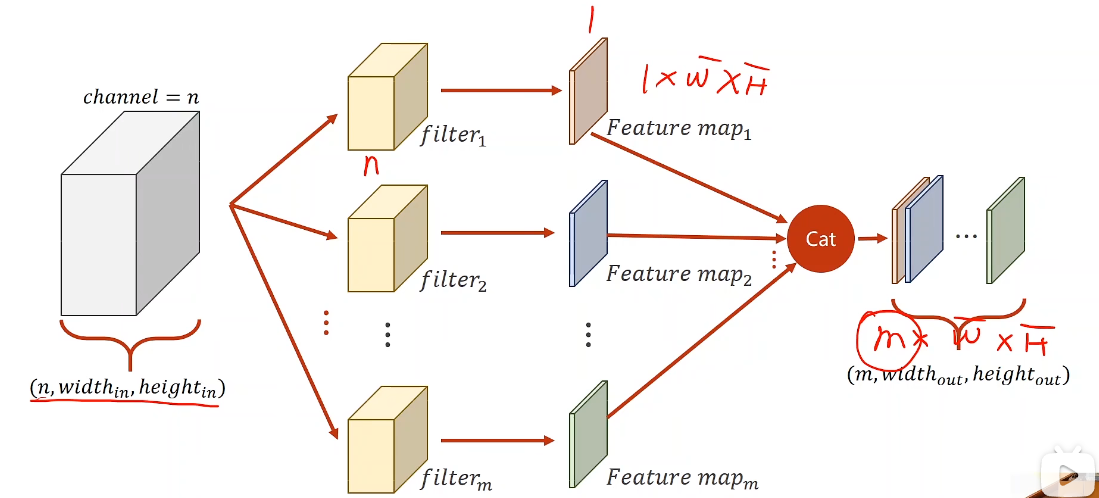
卷积改变通道数:低维到高纬:一个卷积核形成一个新的通道,多个卷积核形成多个通道
- 共同确定卷积核张量大小
- input_channel:输入通道数
- kernel_size: 卷积核矩阵大小
- output_channel:输出通道数量,确定卷积核个数
- 共同确定卷积核张量大小
-
-
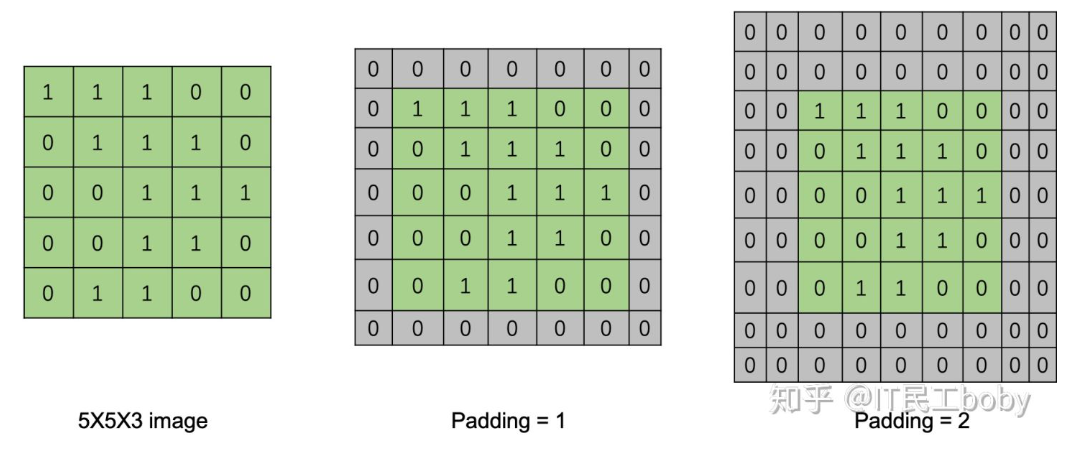
Padding:
-
Padding是在输入矩阵数据周围进行数据填充,常用0来填充。当Padding=1时,在矩阵周围填充一圈,当Padding=2时,填充两圈。
-
为什么要进行Padding?
- 从卷积的计算过程可知,随着卷积操作的进行,图像会越来越小。特别的,当有多个卷积层,图像变小会特别明显。通过Padding可以适当保持图像大小。
- 卷积过程对图片边缘信息和内部信息的重视程序不一样,边缘信息filter只经过一次,而内部信息会被经过多次。通过Padding操作可以缓解信息处理不平衡的问题。
-
-
Stride:卷积步长:提高卷积效率,减少重复计算像素特征
-
卷积输入输出公式:
-
n: 初始图像大小
-
p: padding
-
f: filter大小
-
s:步长
-
-
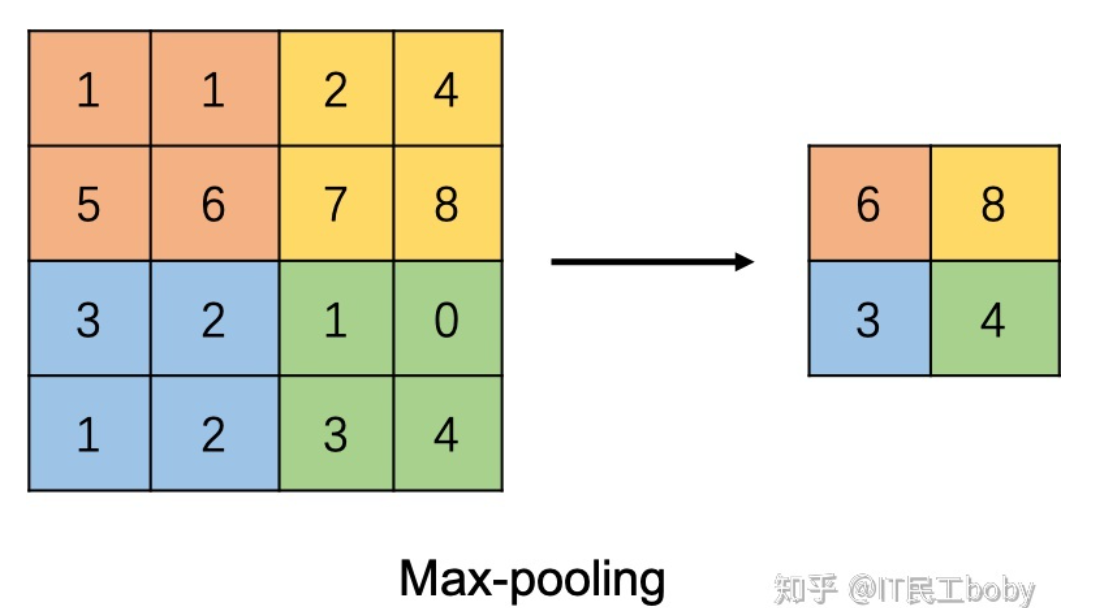
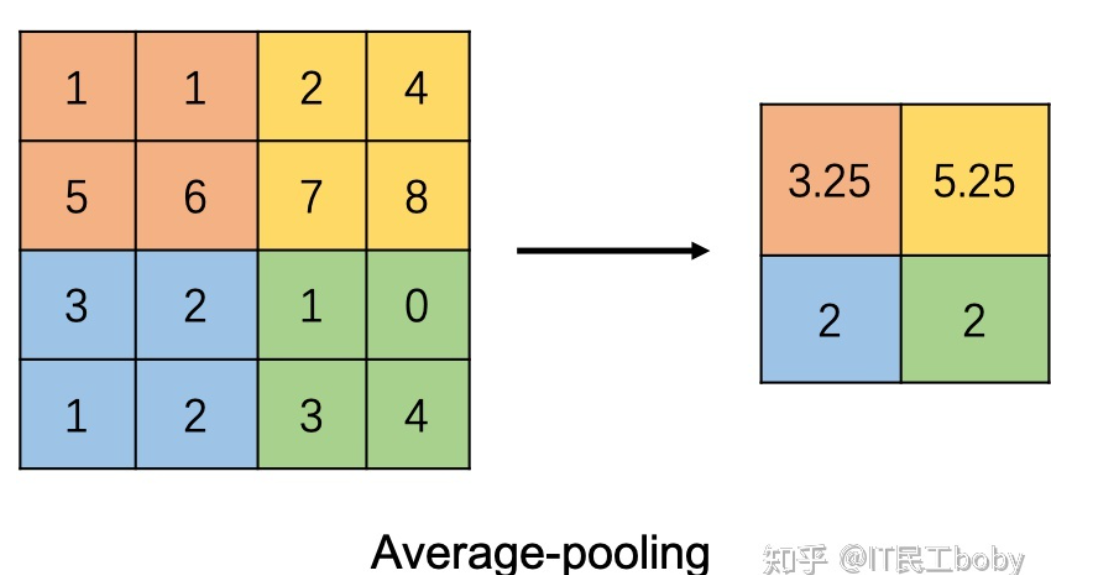
池化层(Pooling Layer)
-
池化层的作用是缩小特征图,保留有用信息,得到一个更小的子图来表征原图。池化操作本质上是对图片进行降采样,可以认为是将一张分辨率高的图片转化为分辨率较低的子图,保留的子图不会对图片内容理解产生太大影响。
-
池化的方式一般有两种:Max Pooling和Average Pooling。
-
Max Pooling:
-
Average Pooling:
-
-
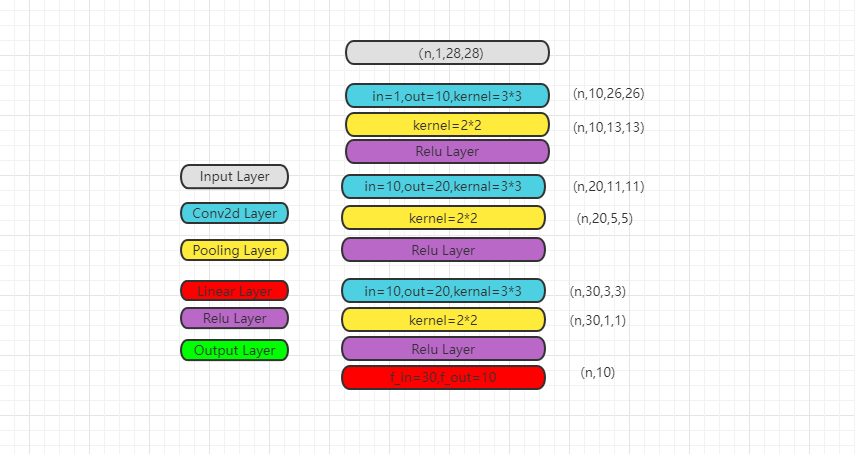
MNIST第一个CNN模型:
-
第一个测试模型:
-
模型代码:
-
class first_CNN(torch.nn.Module): def __init__(self) -> None: super().__init__() self.conv1 = torch.nn.Conv2d(in_channels=1,out_channels=10,kernel_size=3) self.conv2 = torch.nn.Conv2d(in_channels=10,out_channels=20,kernel_size=3) self.conv3 = torch.nn.Conv2d(in_channels=20,out_channels=30,kernel_size=3) self.pooling = torch.nn.MaxPool2d(kernel_size=2) self.liner1 = torch.nn.Linear(in_features=30,out_features=10) self.activate = torch.nn.ReLU() def forward(self,x): # x : n * 1 * 28 * 28 batch_size = x.size(0) out1 = self.activate(self.pooling(self.conv1(x))) # n * 10 * 13 * 13 out2 = self.activate(self.pooling(self.conv2(out1))) # n * 20 * 5 * 5 out3 = self.activate(self.pooling(self.conv3(out2))) # n * 30 * 1 * 1 #flatten input = out3.view(batch_size,-1) # n * 30 #fc layer out = self.liner3(input) return out
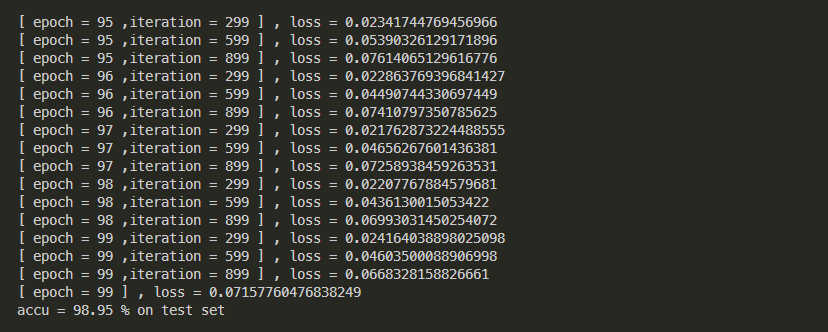
- 100个epoch准确率:
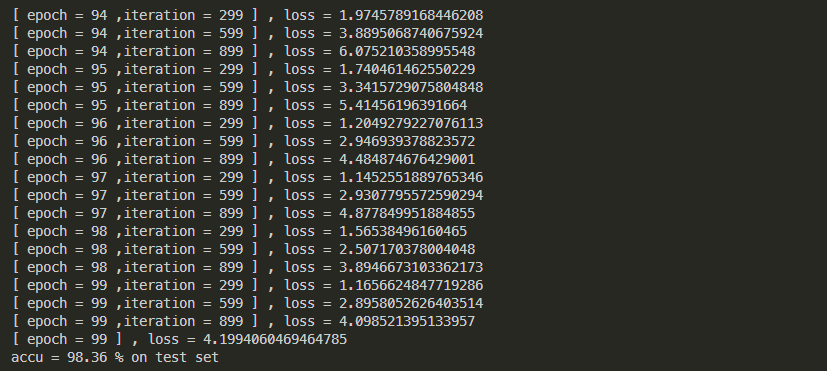
- 第二个CNN模型
- 第二个测试模型:
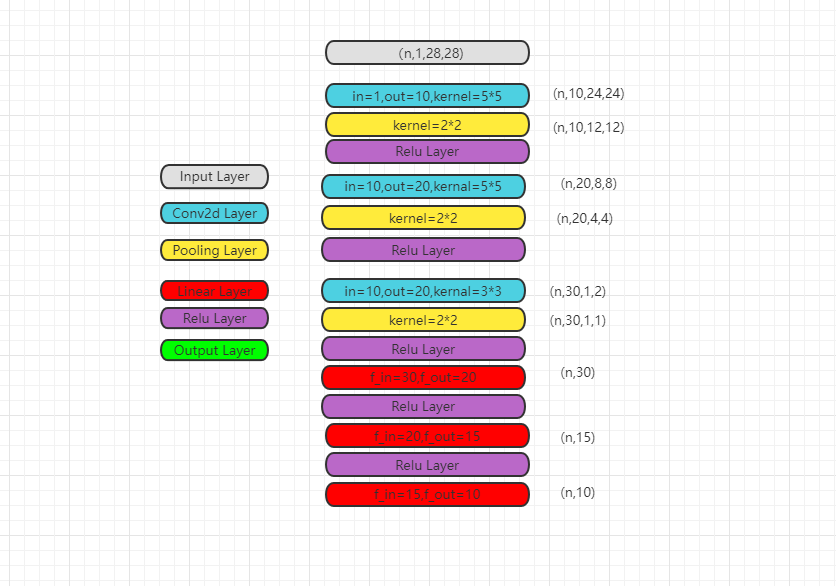
- 模型代码:
- ```python
class first_CNN(torch.nn.Module):
def __init__(self) -> None:
super().__init__()
self.conv1 = torch.nn.Conv2d(in_channels=1,out_channels=10,kernel_size=5)
self.conv2 = torch.nn.Conv2d(in_channels=10,out_channels=20,kernel_size=5)
self.conv3 = torch.nn.Conv2d(in_channels=20,out_channels=30,kernel_size=3)
self.pooling = torch.nn.MaxPool2d(kernel_size=2)
self.liner1 = torch.nn.Linear(in_features=30,out_features=20)
self.liner2 = torch.nn.Linear(in_features=20,out_features=15)
self.liner3 = torch.nn.Linear(in_features=15,out_features=10)
self.activate = torch.nn.ReLU()
def forward(self,x):
# x : n * 1 * 28 * 28
batch_size = x.size(0)
out1 = self.activate(self.pooling(self.conv1(x))) # n * 10 * 12 * 12
out2 = self.activate(self.pooling(self.conv2(out1))) # n * 20 * 4 * 4
out3 = self.activate(self.pooling(self.conv3(out2))) # n * 30 * 1 * 1
#flatten
input = out3.view(batch_size,-1) # n * 30
#fc layer
fc1 = self.activate(self.liner1(input))
fc2 = self.activate(self.liner2(fc1))
out = self.liner3(fc2)
return out
-
-
100epoch准确率:
-
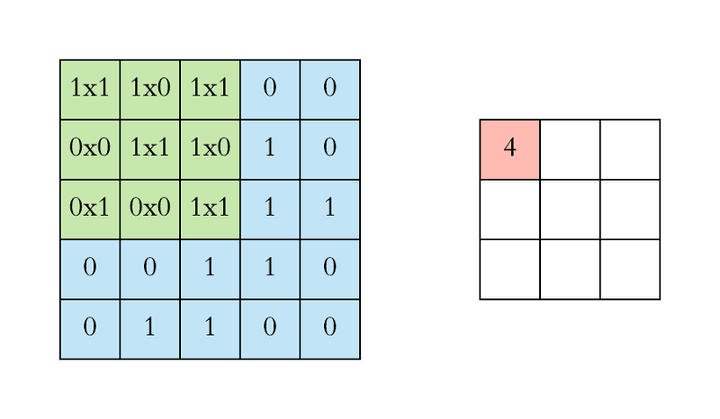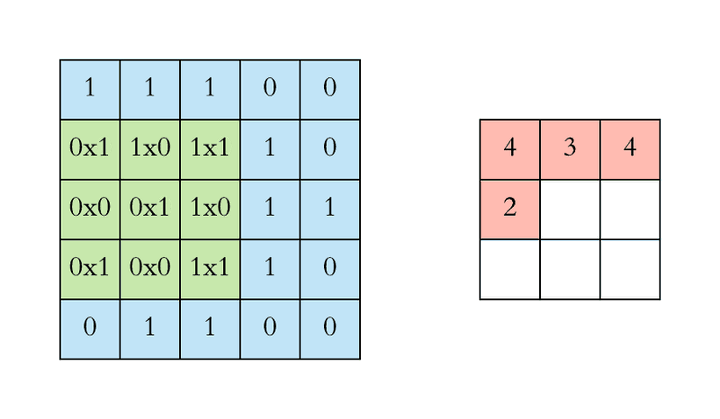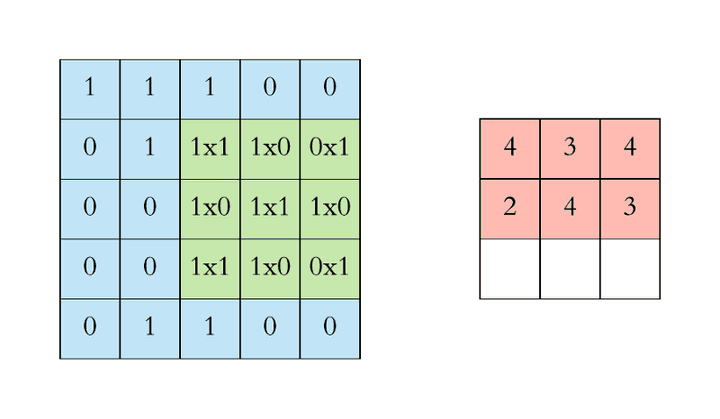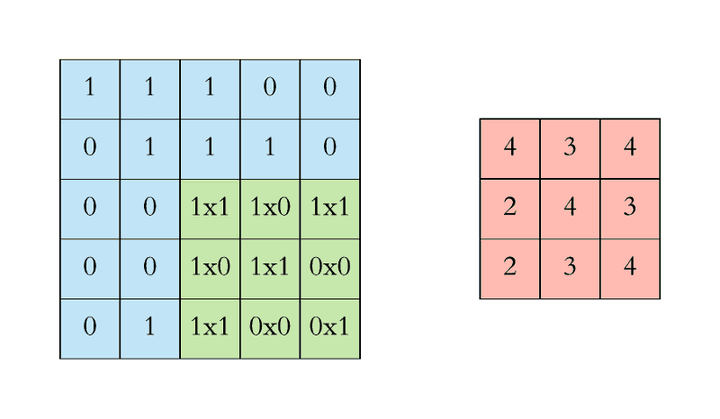
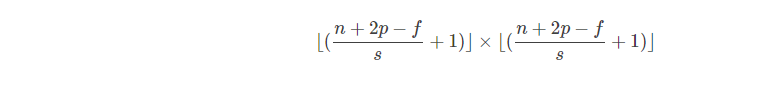
CNN 高阶知识
-
torch.nn与torch.nn.functionaltorch.nn:中都是Module类,例如Relu,Linear,Conv2d等都是类,实例化之后才会初始化参数。通常放在自定义网络模型的__init__()中进行初始化操作,不能放在forward()中因为每次进行forward()操作都会重新实例化该类导致无法持续学习更新参数。torch.nn.functional:torch.nn.functional.x为函数,与torch.nn不同,torch.nn.x中包含了初始化需要的参数等 attributes 而torch.nn.functional.x则需要把相应的weights作为输入参数传递,才能完成运算, 所以用torch.nn.functional创建模型时需要创建并初始化相应参数.通常在__init__()中定义参数,在forward()中传入。
-
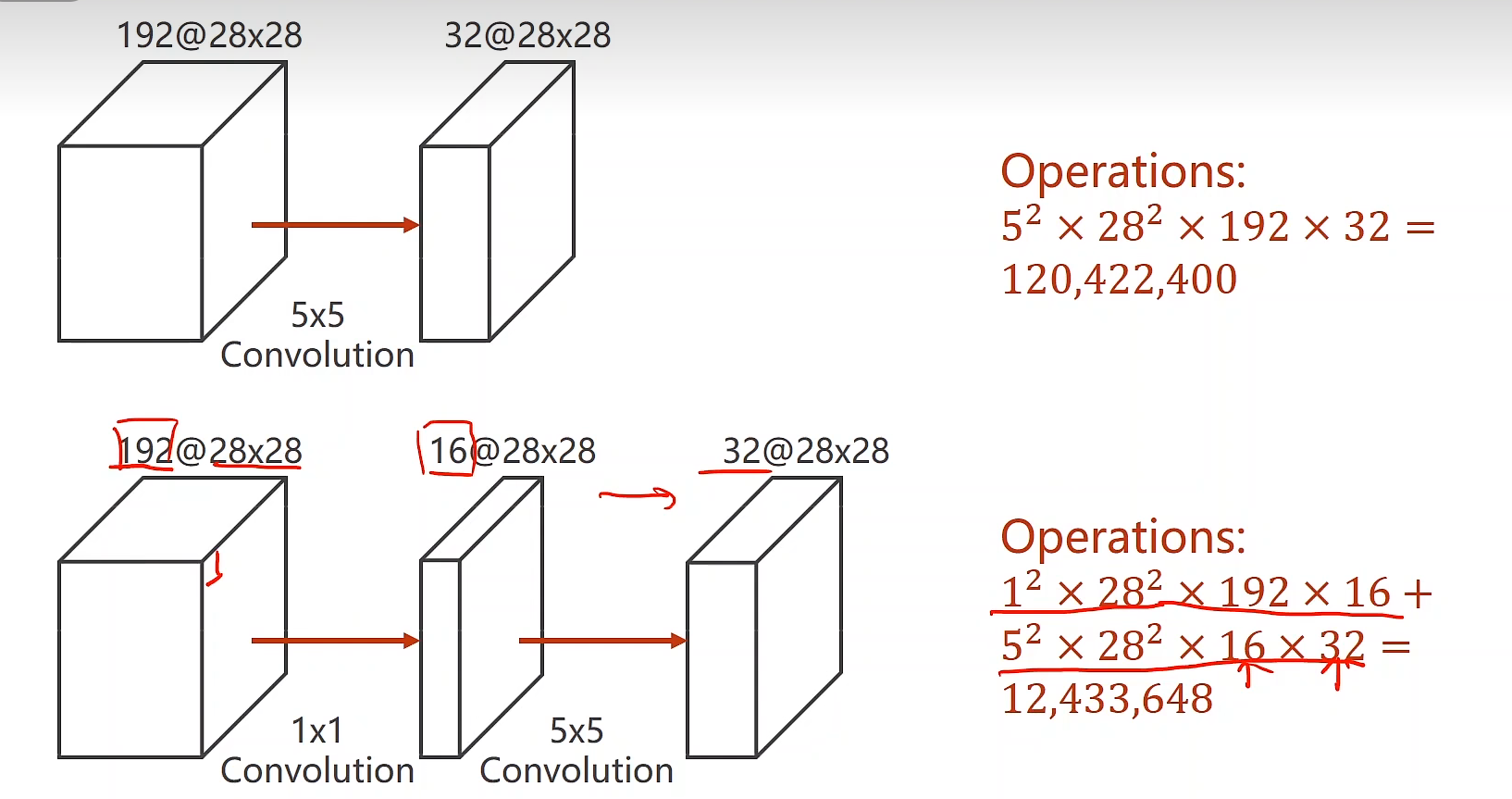
1*1 卷积:减少计算量(network in network)
-
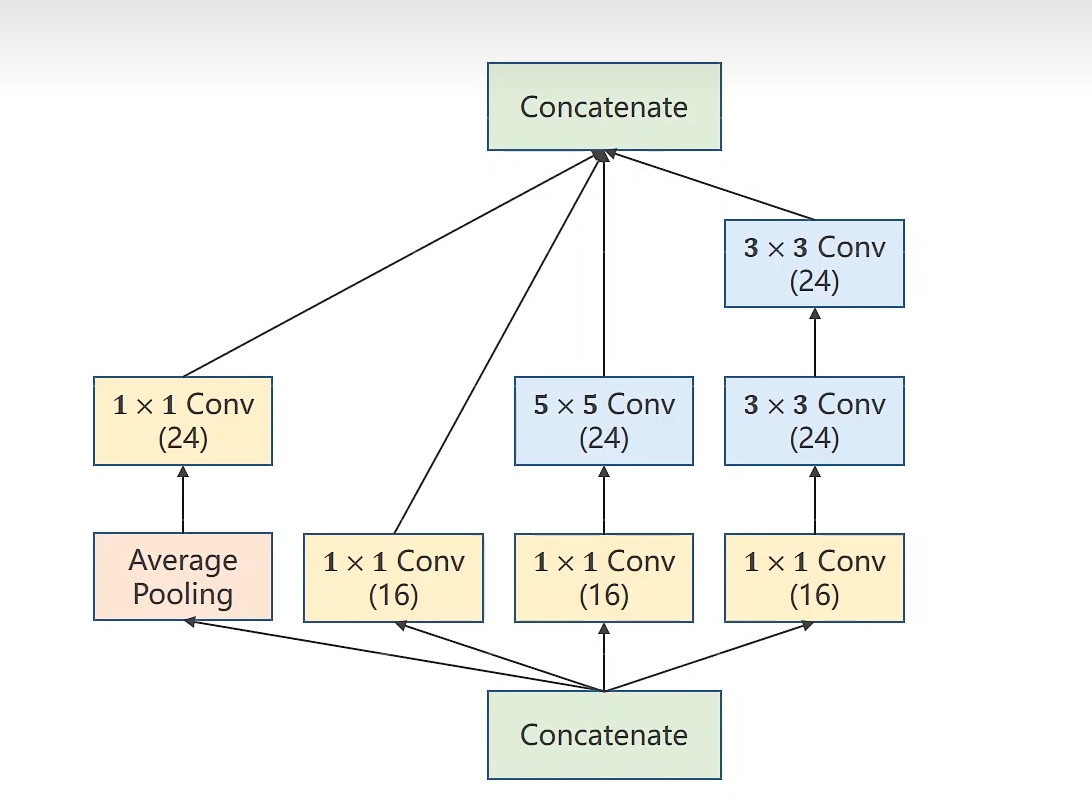
Inception Module: 复杂网络模块化:
-
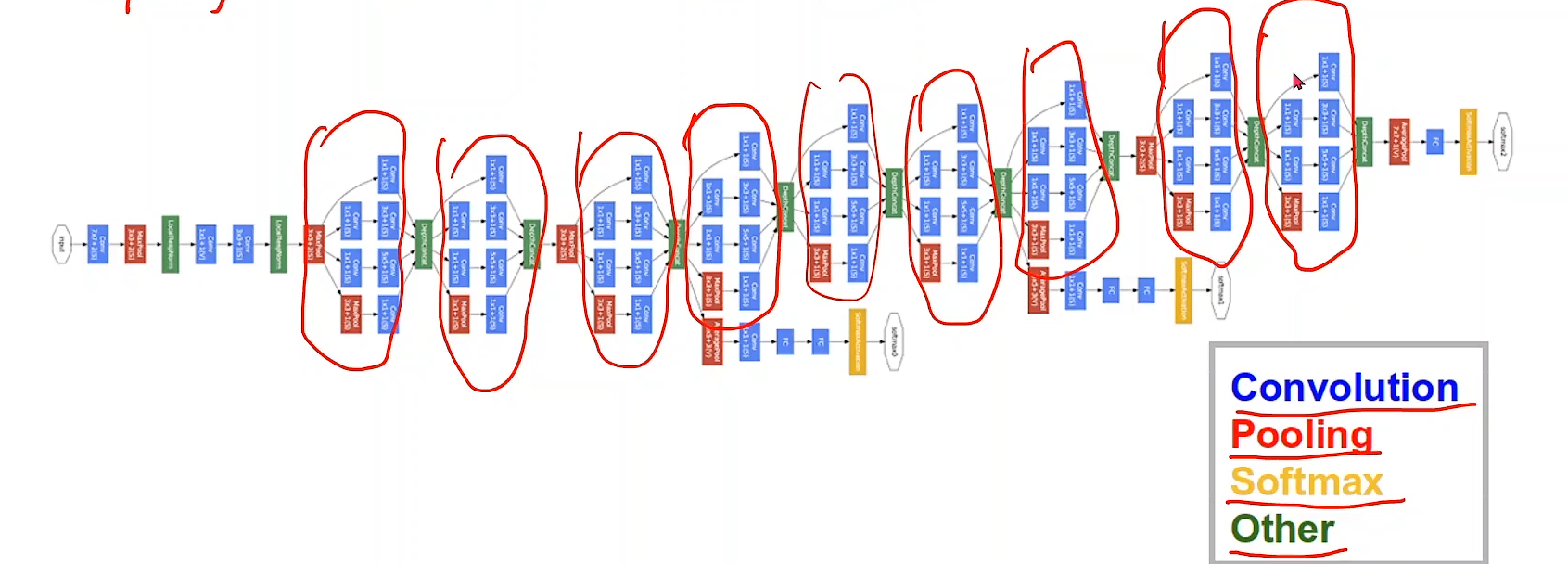
GoogLeNet
-
Example: 输入输出的 H * W 不变,只改变通道数
-
-
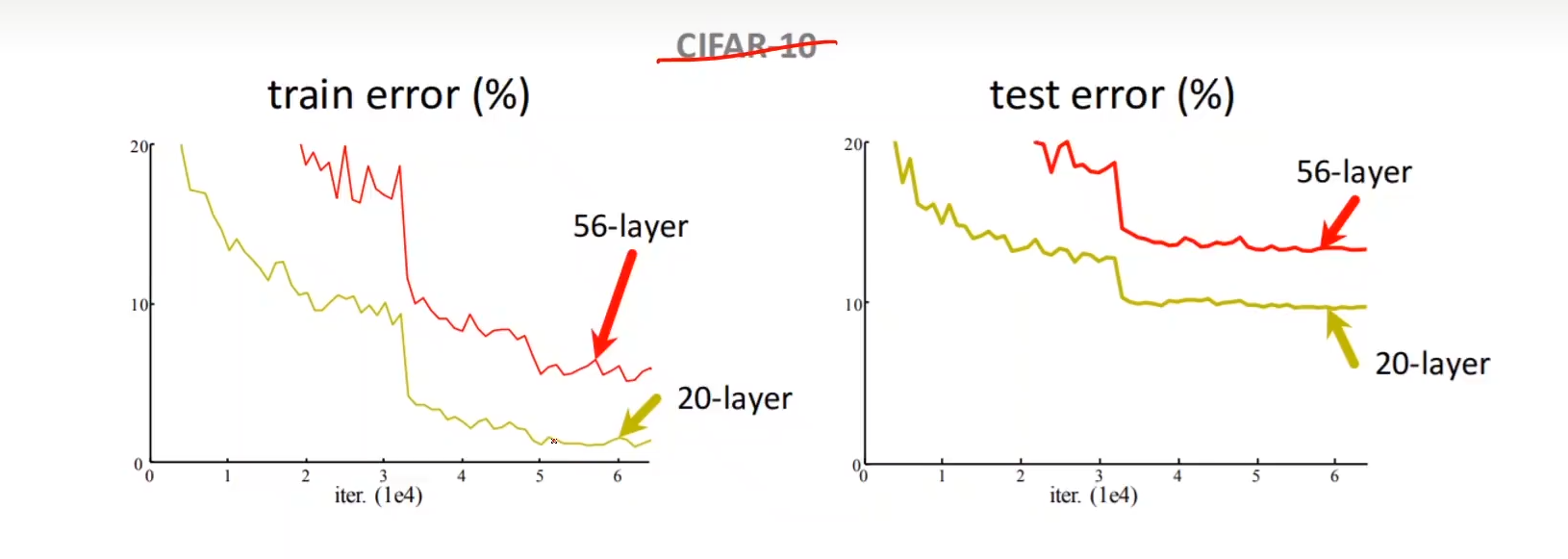
梯度消失
-
反向传播中由于层数过多,导致计算反向传播的梯度时,链式法则中每一项的偏导都很小,乘积趋近于0,导致梯度消失不再进行更新。
-
-
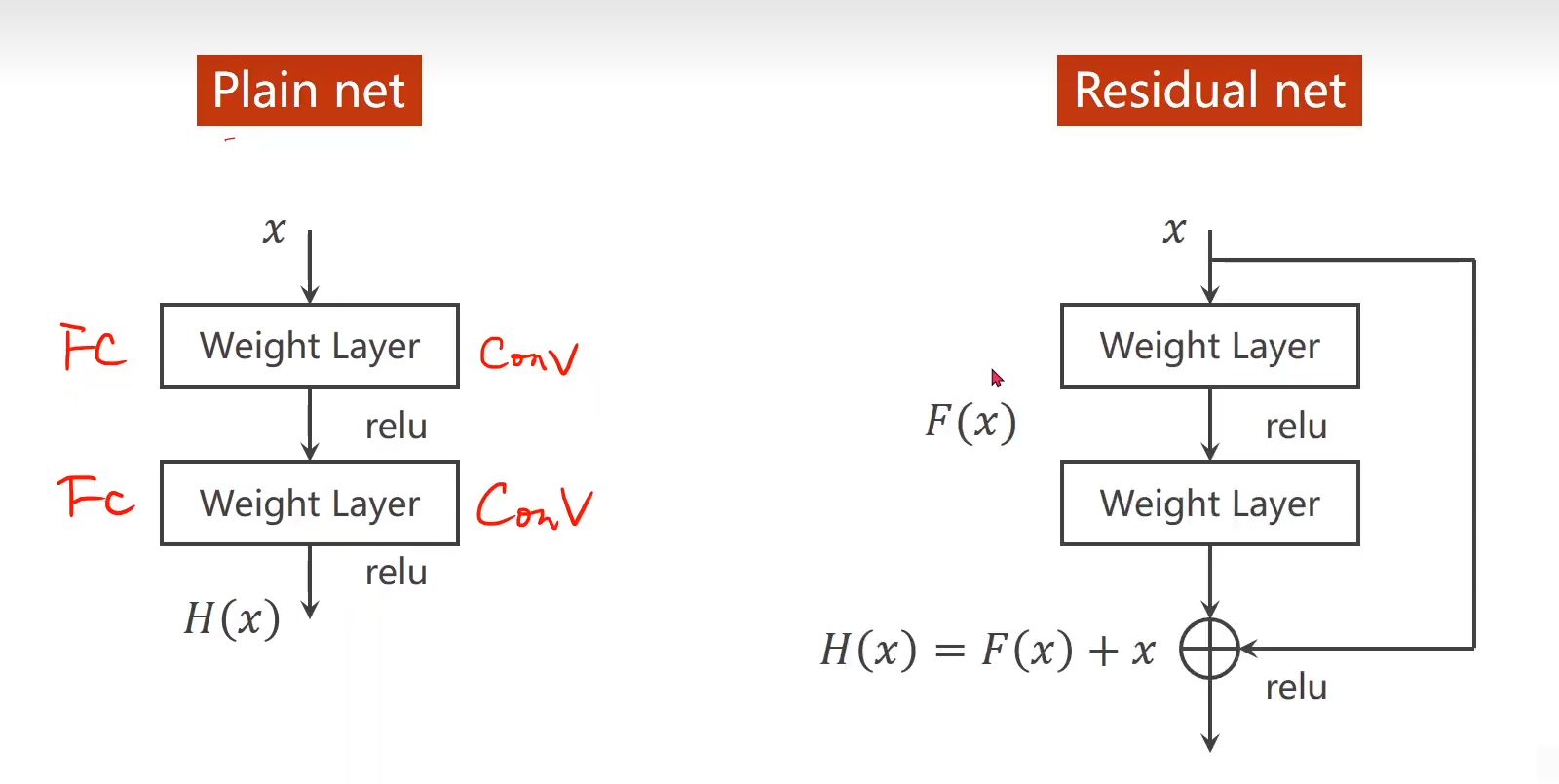
Residual net
-
-
-
Residual net 块中保持输入的 维度不变,才能做 F(x) + x
-
Residual Block:
-
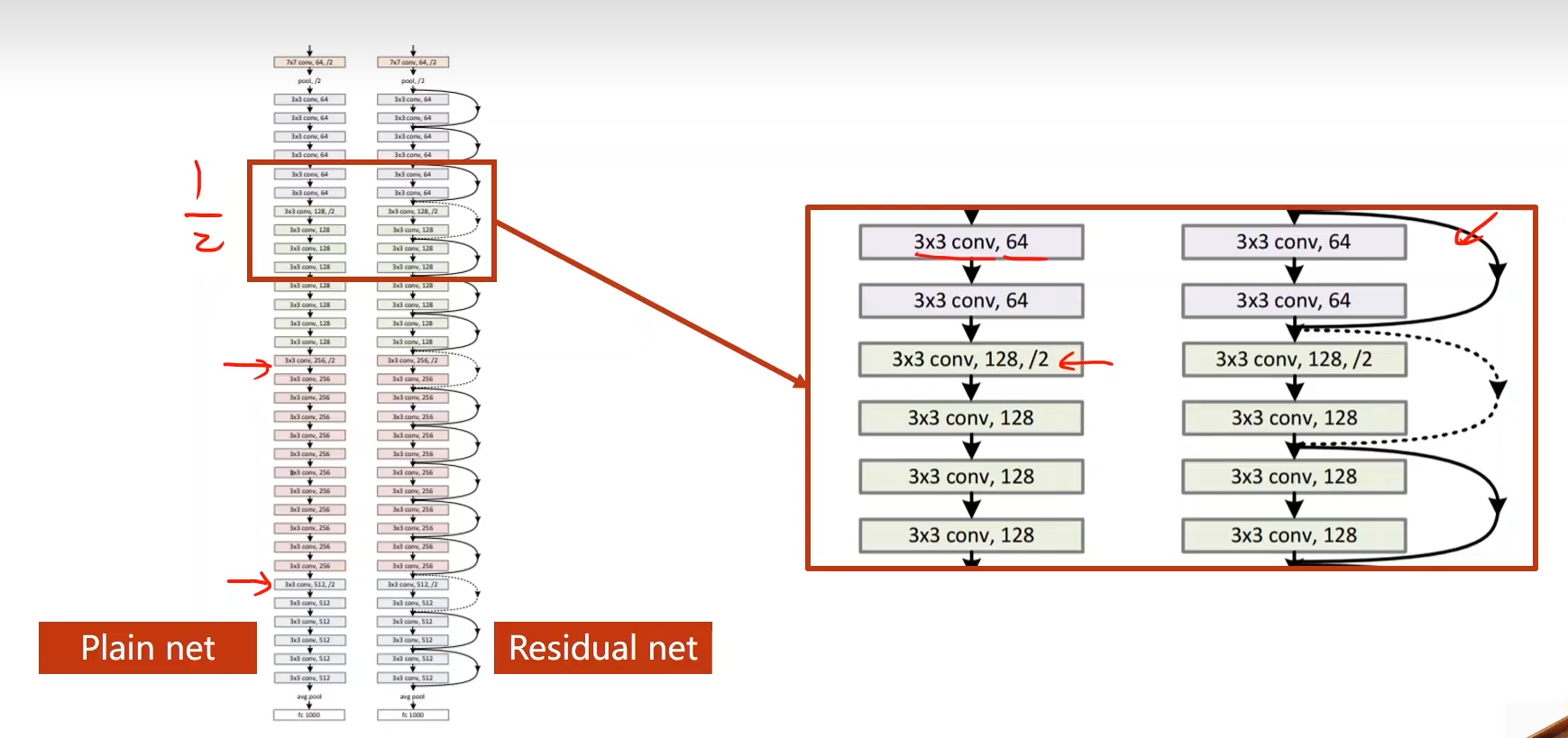
Net
-
-

循环神经网络 RNN Basic
-
处理序列输入特征,前一个特征序列输出值影响后一个特征序列的计算,共享权重
-
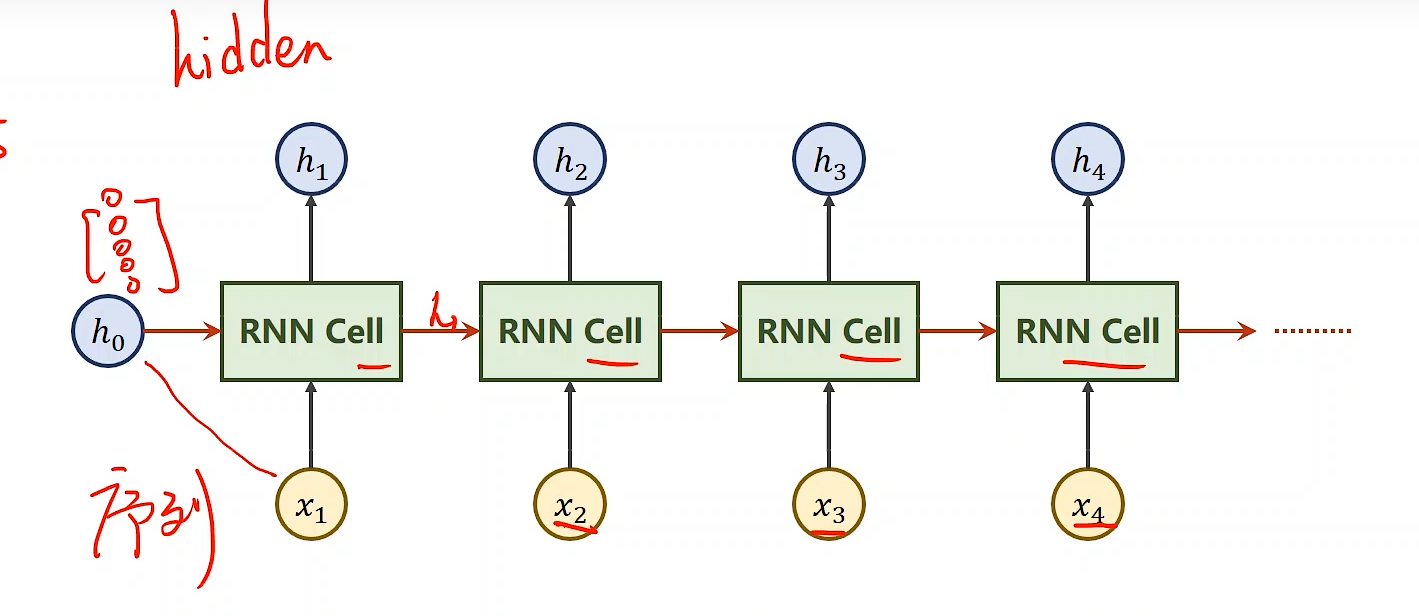
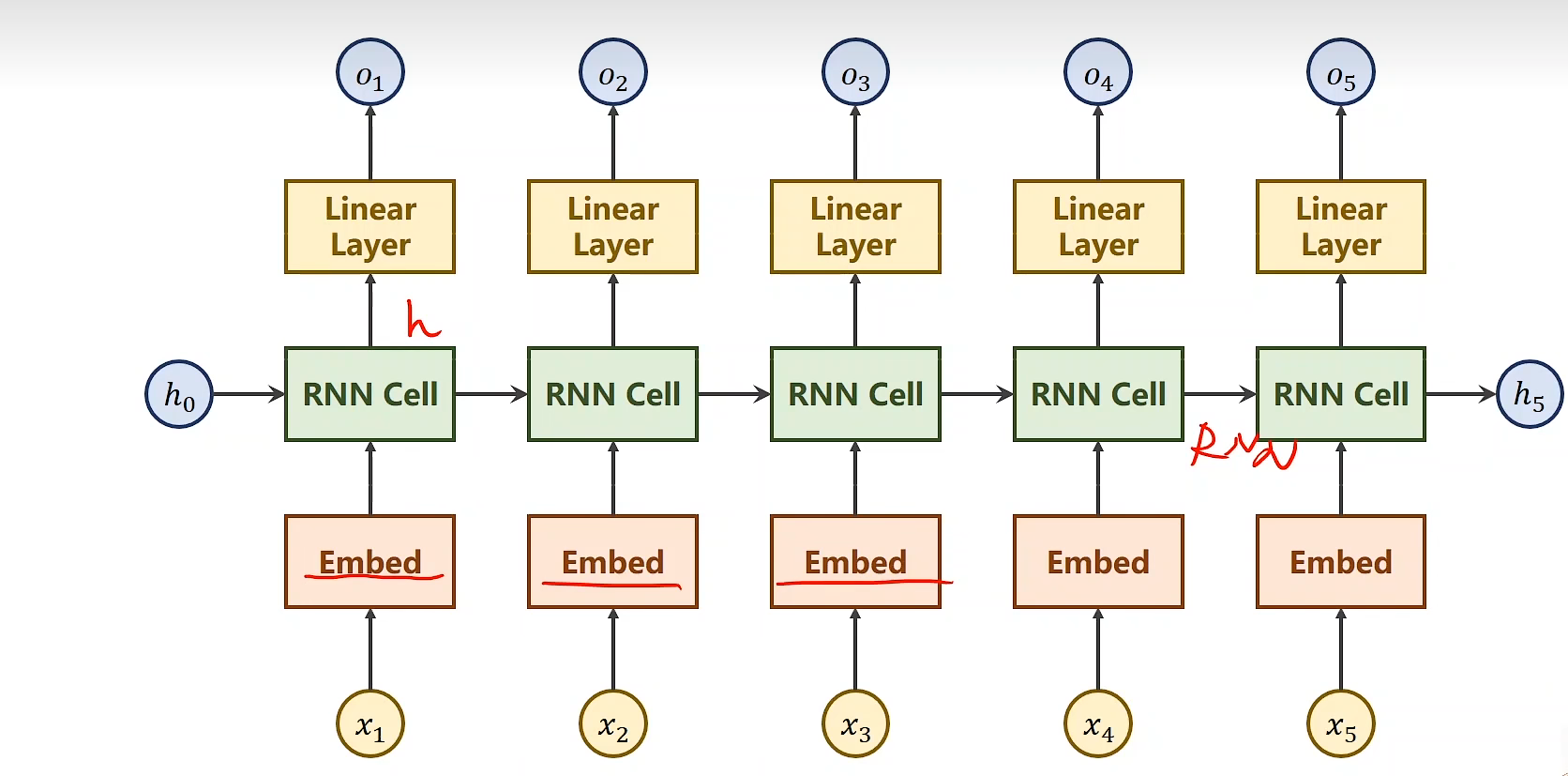
RNN 简单模型
-
-
x1,x2,x3,x4序列中RNN cell共享权重
-
-
计算过程
-
-
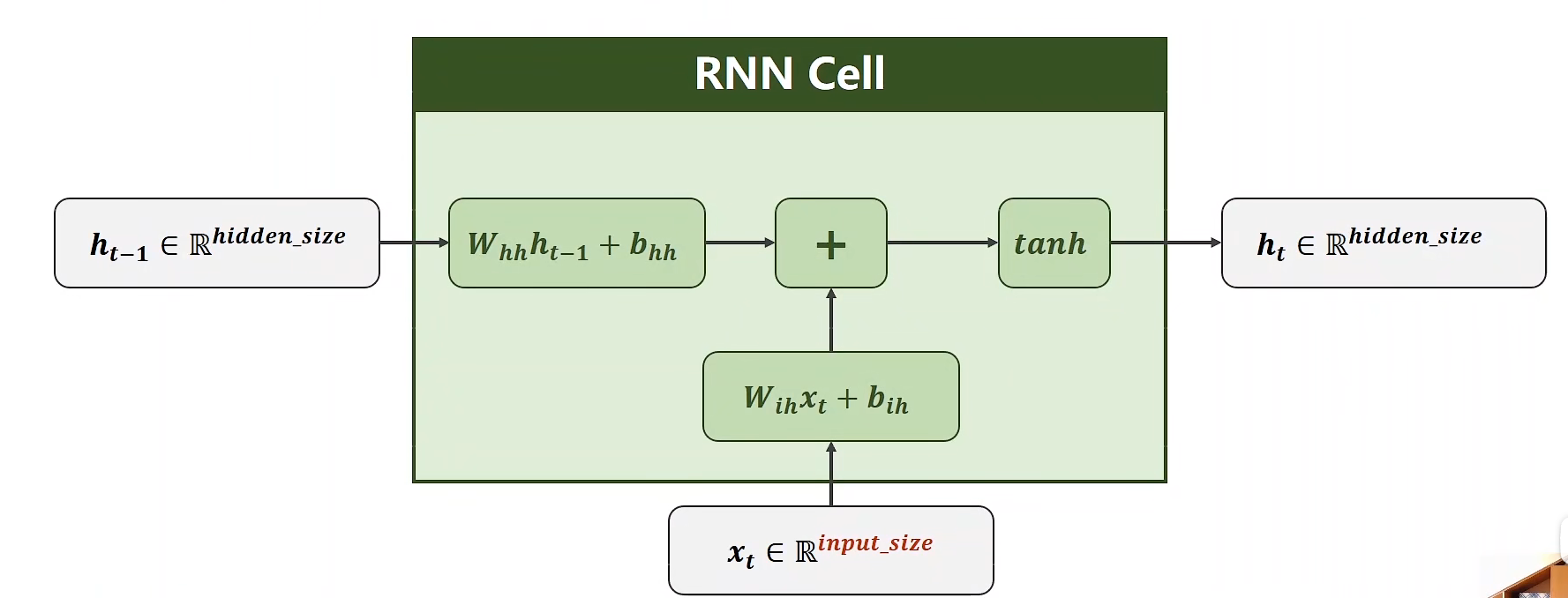
公式:
-
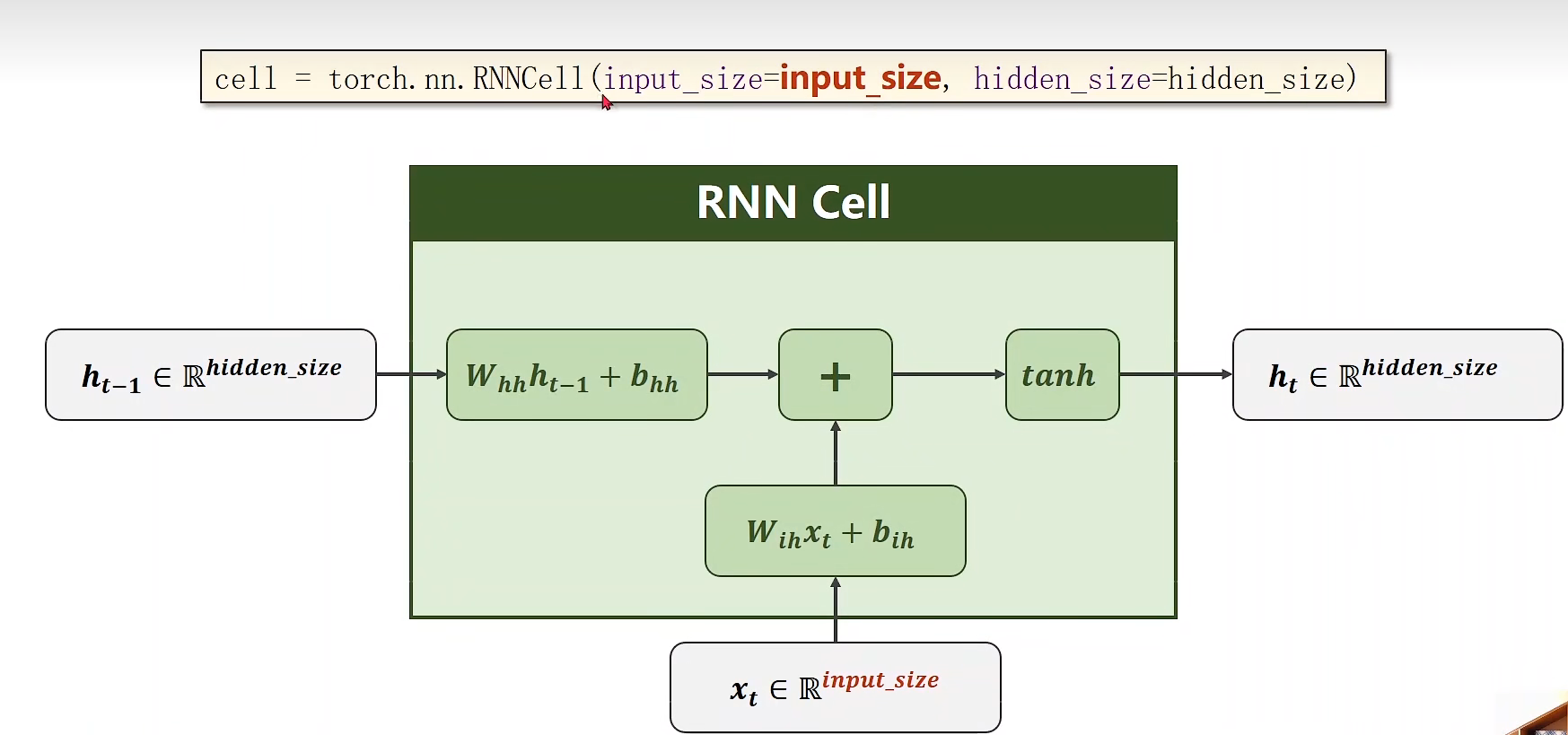
构造RNNcell:
-
-
-
Example:
-
import torch from torch import nn batch_size = 64 seq_len = 3 input_size = 4 hidden_size = 2 rnn = nn.RNNCell(input_size=input_size,hidden_size=hidden_size) dataset = torch.randn(seq_len,batch_size,input_size) hidden = torch.zeros(batch_size,hidden_size) for index,input_seq in enumerate(dataset,0): print("=========================== index = {} ====================================".format(index)) print("input size = {} ".format(input_seq.shape)) # print(input_seq) hidden = rnn(input_seq,hidden) print("hidden size = {}".format(hidden.shape)) # print(hidden)
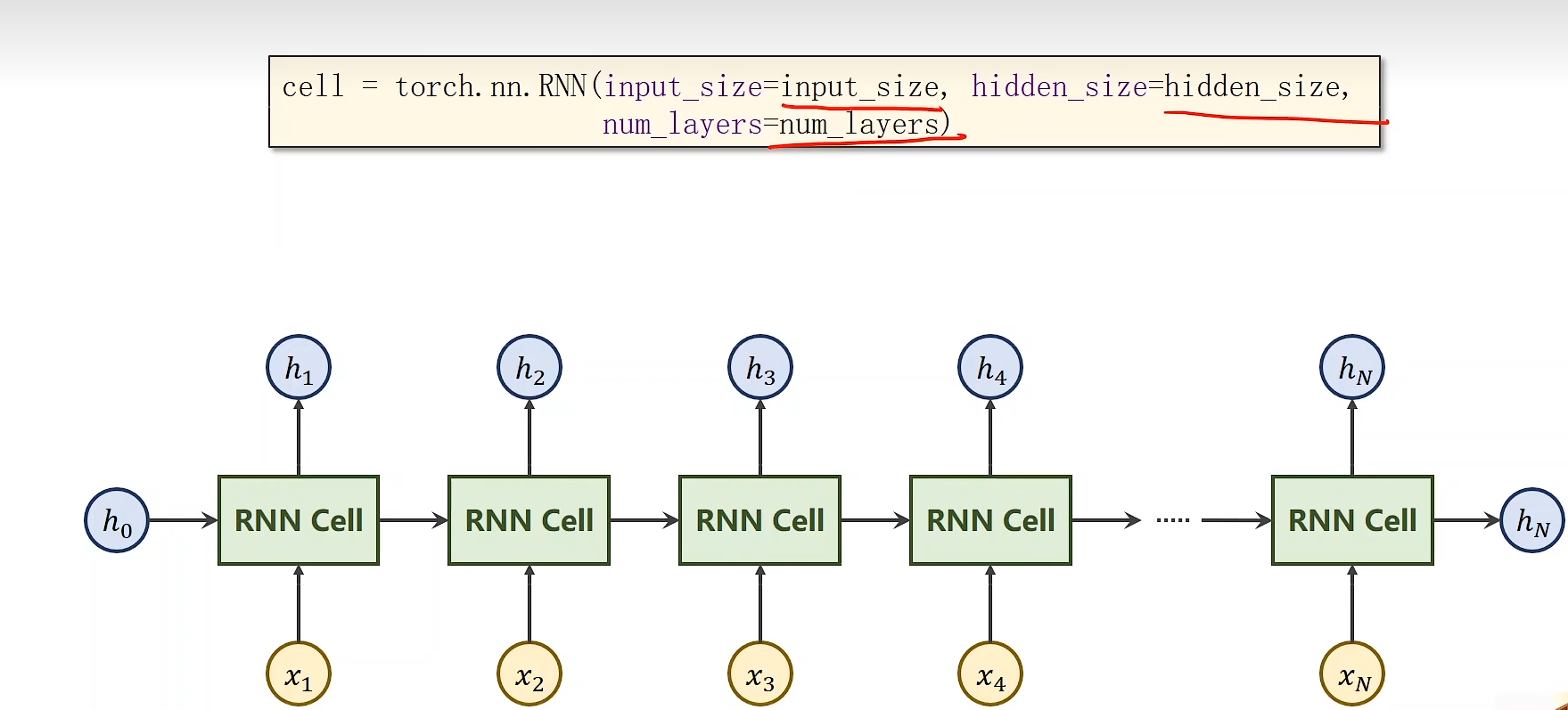
- 构造RNN:
- 
- 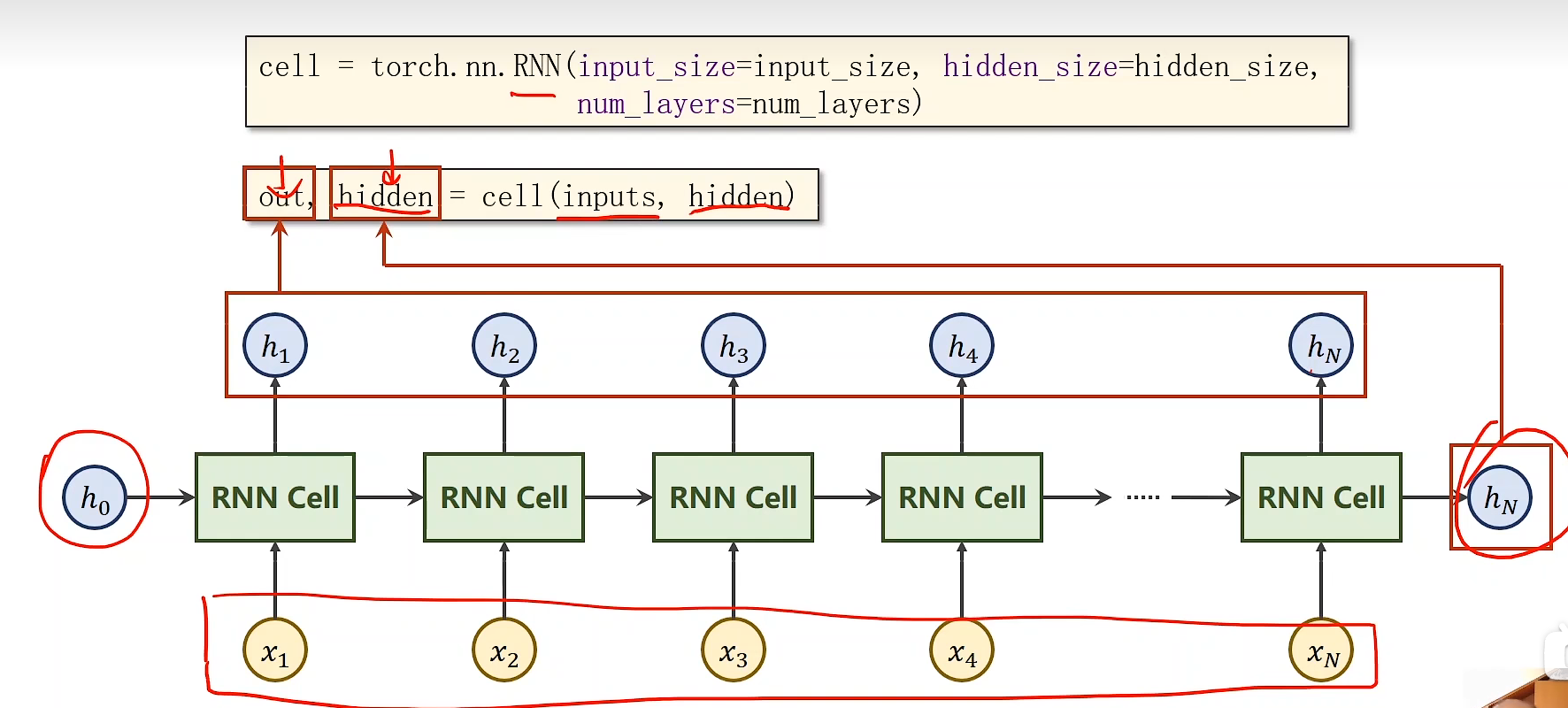
- 输入与输出维度
- 
- Example:
- 
- ```python
import torch
from torch import nn
batch_size = 64
seq_len = 3
input_size = 4
hidden_size = 2
num_layers = 1
dataset = torch.randn(seq_len,batch_size,input_size)
hidden = torch.zeros(batch_size,hidden_size)
hidden_rnn = torch.zeros(num_layers,batch_size,hidden_size)
RNN = nn.RNN(input_size=input_size,hidden_size=hidden_size,num_layers=num_layers)
out,hidden = RNN(dataset,hidden_rnn)
print(out.shape)
print(hidden.shape) -
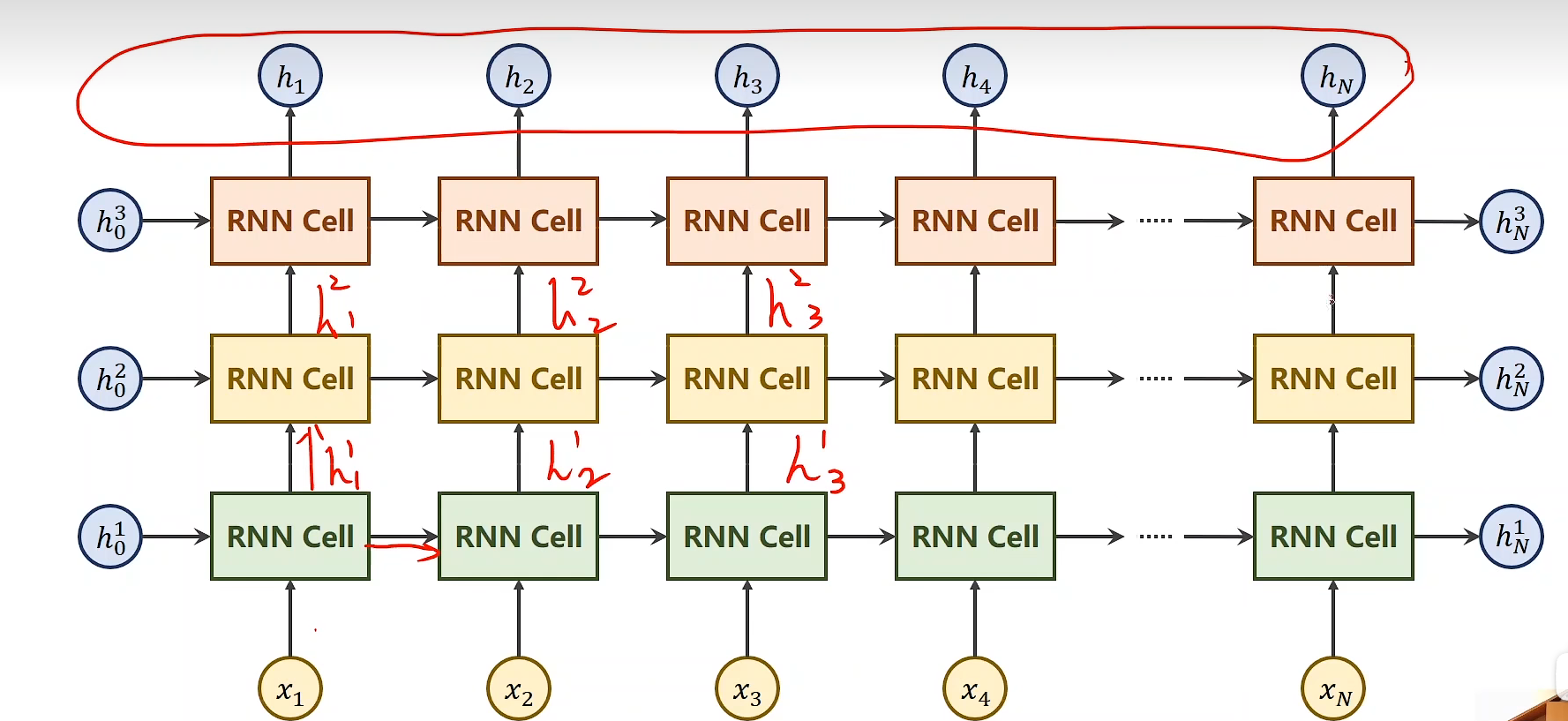
多层:
num_layers != 1:- 每个序列的输出隐藏层结果向上 同时向后 传播作为输入
- 向上作为下一层的输入
- 向后作为下一个序列依赖的输入
- 每个序列的输出隐藏层结果向上 同时向后 传播作为输入
-
其他参数
- batch_first:
- batch_first:
-
-
Example;RNNCELL 模型学习 hello 序列预测 ohlol序列
-
e,h,l,o分别映射为数字0,1,2,3 并采用 One-hot编码代表每个字母特征:
-
import os from re import L import torch import numpy as np from torchvision import transforms,datasets from torch.utils.data import DataLoader import torch.nn as nn import cv2 as cv import torch.nn.functional as F batch_size = 1 seq_len = 5 input_size = 4 hidden_size = 4 num_layers = 1 words = ['e','h','l','o'] x_data = [1,0,2,2,3] # h e l l o y_data = [3,1,2,3,2] # o h l o l one_hot_dict = [[1,0,0,0], [0,1,0,0], [0,0,1,0], [0,0,0,1]] x_one_hot = [one_hot_dict[x] for x in x_data]
- 构建 input数据集:seq_len * batch_size * input_size,构建 labels数据集: seq_len * batch_size
- ```python
inputs = torch.Tensor(x_one_hot).view(-1,batch_size,input_size) # seq * b * input
labels = torch.LongTensor(y_data).view(-1,1) # seq * 1 -
构建 RNNCELL模型:
-
class RNNModule(nn.Module): def __init__(self,batch_size,input_size,hidden_size) -> None: super().__init__() self.batch_size = batch_size self.input_size = input_size self.hidden_size = hidden_size self.rnncell = nn.RNNCell(input_size=self.input_size,hidden_size=self.hidden_size) def forward(self,x,hidden): # x = batch * input_size # hidden = batch * hidden_size hidden = self.rnncell(x,hidden) return hidden def init_hidden(self): return torch.zeros(self.batch_size,hidden_size)
- train:
- ```python
rnnmodule = RNNModule(batch_size=batch_size,input_size=input_size,hidden_size=hidden_size)
)
lossfunc = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(rnnmodule.parameters(),lr=0.1)
def train(epoch):
# h_0 = batch * hidden
hidden = rnnmodule.init_hidden()
loss = 0
optimizer.zero_grad()
for input,label in zip(inputs,labels):
hidden = rnnmodule(input,hidden) # hidden = batch * hidden_size
loss = loss + lossfunc(hidden,label) # label = batch
_,pred = hidden.max(dim=1)
# print("\npred words: ")
print(words[pred.item()],end='')
loss.backward()
optimizer.step()
print('[ epoch = {} ] , loss = {}'.format(epoch,loss.item()))
-
-
-
-
Exampl RNN 模型学习 hello 序列预测 ohlol序列
-
前期数据处理其余与RNNCELL一致,lables数据集:(seq_len * batch_size)
-
labels1 = torch.LongTensor(y_data) # seq
- 完整code:
- ```python
class RNNModule1(nn.Module):
def __init__(self,batch_size,input_size,hidden_size,num_layers) -> None:
super().__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size=self.input_size,hidden_size=self.hidden_size,num_layers=self.num_layers)
def forward(self,x):
# h = num_layers * batch * hidden
hidden = torch.zeros(self.num_layers,self.batch_size,self.hidden_size)
# return (out,h_n) out = seq * batch * hidden_size
out,_ = self.rnn(x,hidden)
return out.view(-1,self.hidden_size)
rnnmodule1= RNNModule1(batch_size=batch_size,input_size=input_size,hidden_size=hidden_size,num_layers=num_layers)
lossfunc = torch.nn.CrossEntropyLoss()
optimizer1 = torch.optim.SGD(rnnmodule1.parameters(),lr=0.05)
def train1(epoch):
optimizer.zero_grad()
out = rnnmodule1(inputs) # out = seq * batch * hidden_size
loss = lossfunc(out,labels1) # labels = (seq * batch)
_,pred = out.max(dim=1)
for index in pred:
print(words[index.item()],end='')
loss.backward()
optimizer1.step()
print('[ epoch = {} ] , loss = {}'.format(epoch,loss.item()))
-
-
-
One-hot编码
-
另一种方式:
-
Embedding理解:
-
embedding 管理着一个大小固定的二维向量权重,其input输入值它首先转化为one-hot编码格式,将转化为后的one-hot 与权重矩阵做矩阵乘法,就得到了每一个input的embedding输出。由于这个embedding权重是可训练的,所以在最训练后的权重值,能够表达不同字母之间的关系。
- batch_size * volcabulary_size . volcabulary_size * embedding_size
-
-
加上embed 层模型:
-
-
inputs 与 labels 数据集:
-
inputs: (seq,batch_size),embed层的
*num_embeddings*=*self*.input_size会指定对应的one_hot编码,再进行embed -
labels 由于采用 rnn模型,输出为:(seq * batch_size,num_class),labels维度:(seq * batch_size)
-
import os from re import L import torch import numpy as np from torchvision import transforms,datasets from torch.utils.data import DataLoader import torch.nn as nn import cv2 as cv import torch.nn.functional as F batch_size = 1 seq_len = 5 input_size = 4 hidden_size = 8 num_class = 4 num_layers = 2 words = ['e','h','l','o'] x_data = [1,0,2,2,3] # h e l l o y_data = [3,1,2,3,2] # o h l o l inputs = torch.LongTensor(x_data).view(seq_len,batch_size) #no need to transfer to one hot,embed will do it and then embeded one-hot code labels = torch.LongTensor(y_data)
- 模型:
- ```python
class RNN_EmbeddingModule(nn.Module):
def __init__(self,input_size,hidden_size,batch_size,num_layers) -> None:
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.batch_size = batch_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size = 10,hidden_size=self.hidden_size,num_layers=num_layers)
self.embed = nn.Embedding(num_embeddings=self.input_size,embedding_dim=10)
self.linear = nn.Linear(in_features=self.hidden_size,out_features=num_class)
def forward(self,x):
hidden_0 = torch.zeros(self.num_layers,self.batch_size,self.hidden_size)
embeded = self.embed(x) # embeded = seq * batch * embedding_dim
hidden,_ = self.rnn(embeded,hidden_0) # hidden = seq * batch * hidden
out = self.linear(hidden) # out = seq * batch * num_class
out = out.view(-1,num_class)
return out
-
-
-
-
LSTM
- 在一个时间序列中,不是所有信息都是同等有效的,大多数情况存在“关键词”或者“关键帧”
- 我们会在从头到尾阅读的时候“自动”概括已阅部分的内容并且用之前的内容帮助理解后文
基于以上这两点,LSTM的设计者提出了“长短期记忆”的概念——只有一部分的信息需要长期的记忆,而有的信息可以不记下来。同时,我们还需要一套机制可以动态的处理神经网络的“记忆”,因为有的信息可能一开始价值很高,后面价值逐渐衰减,这时候我们也需要让神经网络学会“遗忘”特定的信息
-
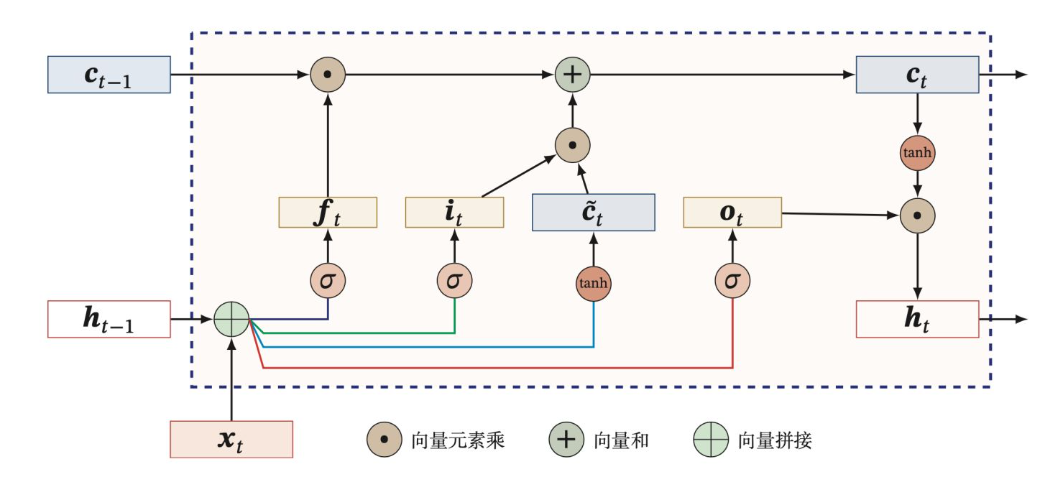
内部结构
-
公式
-
先利用上一时刻的外部状态 ht−1 和当前时刻的输入 xt ,计算出三个门的值(式1.1-1.3),以及候选状态 c~t (式1.4);
-
结合遗忘门 ft 和输入门 it 来更新内部状态 ct ,也称为记忆单元;(记住遗忘门 ft 是针对上一时刻的内部状态ct−1,输入门 it 是针对当前时刻的候选状态 c~t ,如式1.5)
-
结合输出门 ot ,将内部状态 ct 的信息传递给外部状态 ht (式1.6)。
-
其中,1.1-1.4是比较好记的,输入都是 xt 和 ht−1 , W,U,b 是需要学习的网络参数。前三个使用sigmoid是因为输出为[0,1]之间的值,控制信息传播;第四个使用tanh进行非线性计算候选状态,更重要的是相比sigmoid激活函数,其导数有比较大的值域,能缓解梯度消失的问题,照理说tanh也存在梯度饱和的问题,用其他激活函数应该也是可以的。
1.5计算内部状态 ct ,也就是记忆单元,是LSTM核心部分,通过遗忘门和输入门分别乘以上一时刻内部状态 ct−1 和当前时刻的候选状态 c~t ;
1.6就是通过输出门计算非线性激活后的记忆单元tanh(ct) **,**得到当前时刻外部状态 ht 。
-
其实,传统RNN中的ht 存储着历史信息,但是 ht 每个时刻都会被重写,因此可以看做一种短期记忆。长期记忆可以看做是网络内部的某些参数,隐含了从数据中学到的经验,其更新周期要远远比短期记忆慢。
而在LSTM网络中,内部状态 ct 可以在某个时刻捕捉关键信息,并有能力将此关键信息保存一定的时间间隔,看式1.5,如何保存关键信息可以通过遗忘门 ft 和输入门 it 进行控制,因此内部状态 ct 保存信息的周期要长于短期记忆,但又要短于长期记忆,因此成为长短期记忆,即指长的”短期记忆“。
-
GRU(折中)
-
相比LSTM,使用GRU能够达到相当的效果,并且相比之下更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU。
-
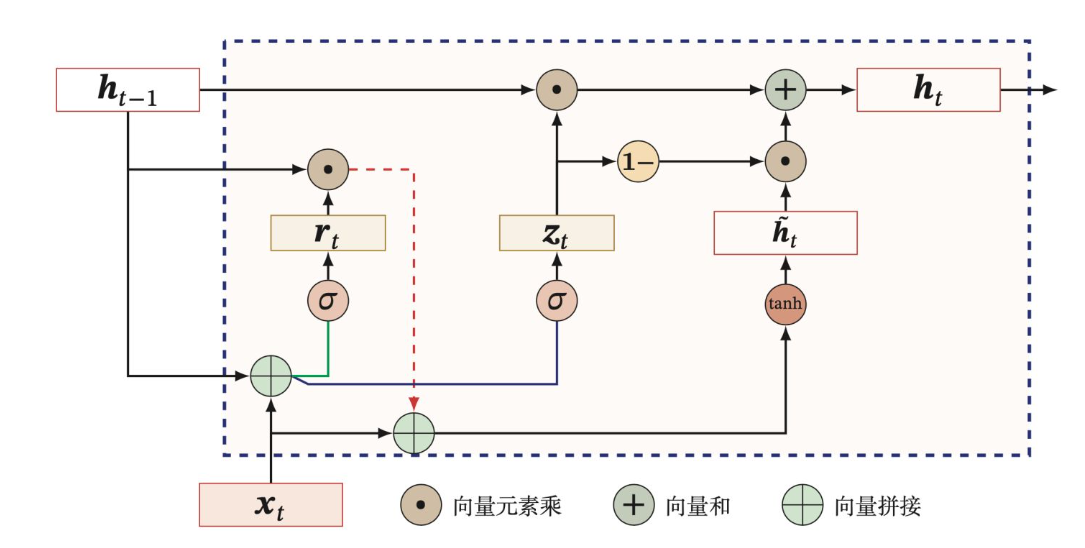
内部结构
-
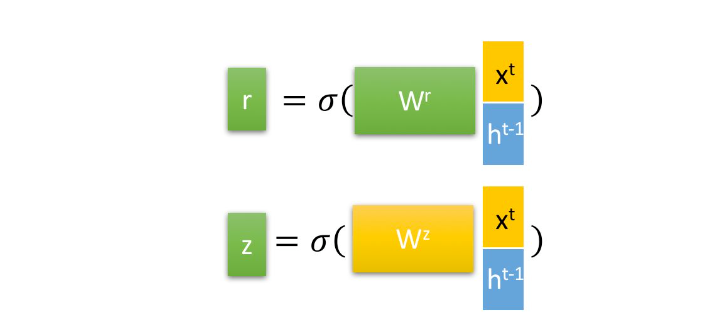
更新门与重置门
-
-
重置门
-
重置门 rt :用来控制候选状态 h~t 的计算是否依赖上一时刻状态 ht−1
-
得到门控信号之后,首先使用重置门控来得到**“重置”之后的数据 ht−1′=ht−1⊙r ,再将 ht−1′ 与输入 xt 进行拼接,再通过一个tanh激活函数来将数据放缩到-1~1**的范围内。即得到如下图2-3所示的 h′ 。
-
- 这里的 h′ 主要是包含了当前输入的 xt 数据。有针对性地对 h′ 添加到当前的隐藏状态,相当于”记忆了当前时刻的状态“。类似于LSTM的选择记忆阶段
-
-
更新门
- 更新门 zt :控制当前状态 ht 需要从上一时刻状态 ht−1 中保留多少信息(不经过非线性变换),以及需要从候选状态 h~t 中接受多少信息;
-
GRU直接使用更新门来控制输入和遗忘的平衡,而LSTM中输入门和遗忘门相比GRU就具有一定的冗余性了。可以看出,当 zt=0 时,当前状态 ht 和上一时刻状态 ht−1 为非线性关系;当 zt=1 时, ht 和 ht−1 为线性关系。
-
-
-
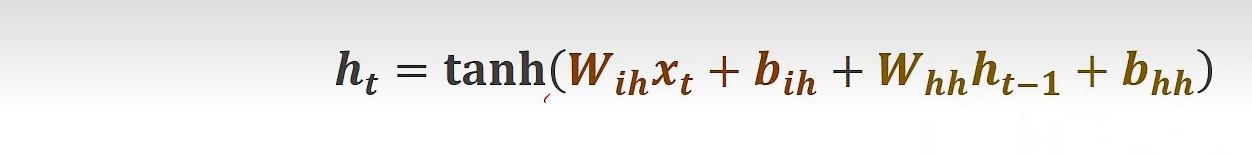





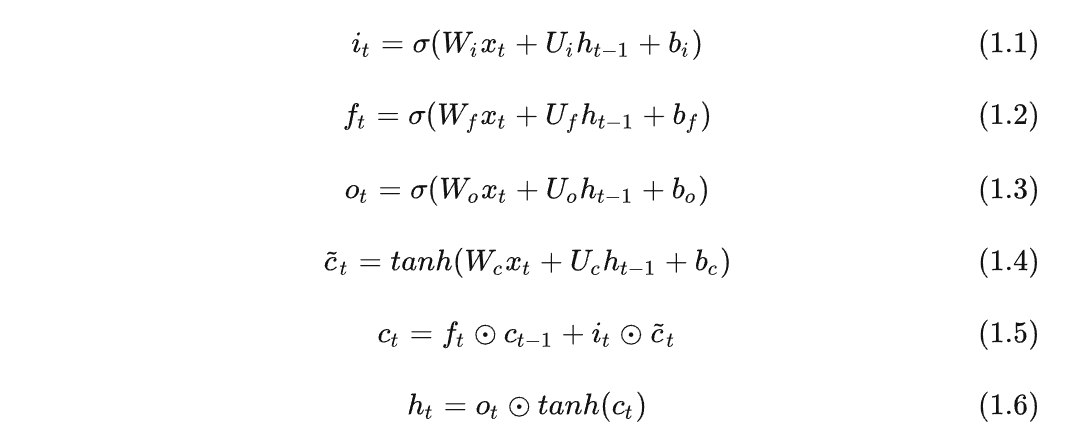

循环神经网络 RNN Advanced
根据姓名进行国籍预测
数据集:
链接:https://pan.baidu.com/s/1W_lfkQbjAl0E66IidtRQNw |
-
模型:
-
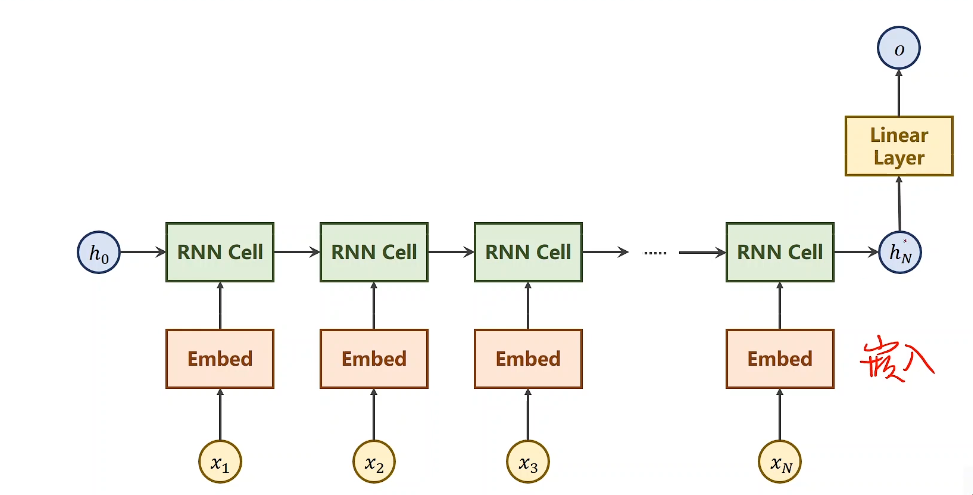
单向
-
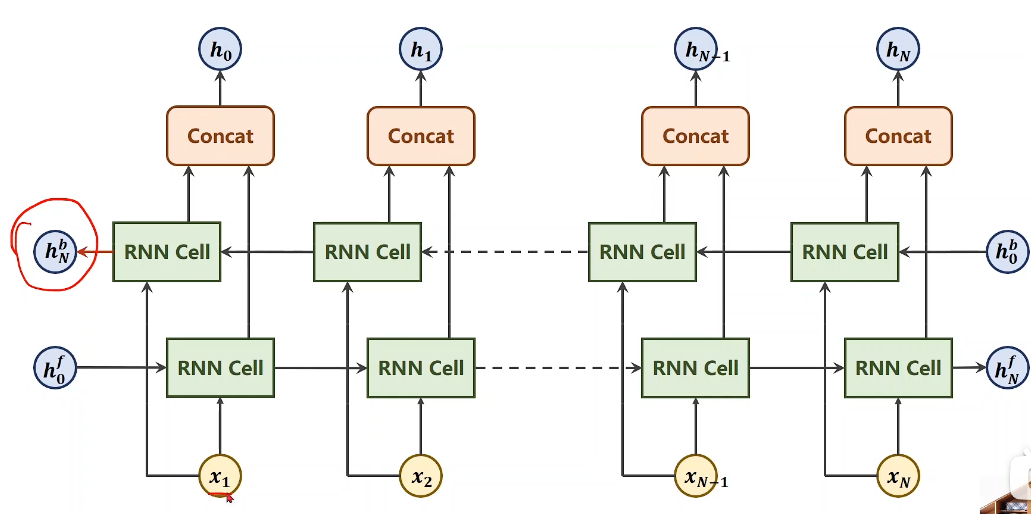
双向:
-
-
全局参数
-
INPUT_SIZE= 128 HIDDEN_SIZE = 100 BATCH_SIZE = 256 NUM_LAYERS = 2 USE_GPU = True EPOCH = 200 LR = 0.1 BIDIRECTION = False device = torch.device(device='cuda')
- 制作数据集:
- Dataset 返回 (nameslist,countrycode_list)
- ```python
class NameDataSet(Dataset):
def __init__(self,train:bool=True, batch_size:int=BATCH_SIZE, path:str=None) -> None:
super().__init__()
train_file = 'NAME_LIST/names_train.csv'
test_file = 'NAME_LIST/names_test.csv'
data_path = [train_file,test_file]
if path is None:
if train:
file = data_path[0]
else:
file = data_path[1]
else:
file = path
data = pd.read_csv(file,header=None)
data.columns=['names','countries']
self.batch_size = batch_size
self.len = len(data)
self.names_list = data['names'].tolist()
self.countries = data['countries'].tolist()
self.country_list = sorted(set(self.countries))
self.country_num = len(self.country_list)
self.country_codelist = [self.getCountryIndex(country=country) for country in self.countries]
def __getitem__(self, index):
return (self.names_list[index],self.country_codelist[index]) # (batch,seq)
def __len__(self):
return self.len
def getCountryIndex(self,country:str):
country_dict = dict()
for index,countryname in enumerate(self.country_list):
country_dict[countryname] = index
return country_dict[country] -
Dataloader 返回 (batchsize,),(batchsize,)
-
train_data = NameDataSet(train=True,batch_size=BATCH_SIZE) test_data = NameDataSet(train=False,batch_size=BATCH_SIZE) coun_dit = test_data.country_list trainloader = DataLoader(train_data,batch_size=BATCH_SIZE,shuffle=True,num_workers=8) testloader = DataLoader(test_data,batch_size=BATCH_SIZE,shuffle=True,num_workers=8)
- 制作模型输入数据:
- Input:Tensor,shape(seqlen,batchsize)
- countrycode:Tensorshape(batchsize,)
- seqlen_list:Tensor,shape(batchsize,)
- ```python
def make_tensors(data_loader):
name_list , countries_code = data_loader
seqlen_list = [len(name) for name in name_list]
max_len = max(seqlen_list)
ascii_list = np.zeros((len(name_list),max_len))
for index,data in enumerate(zip(name_list,seqlen_list),0):
name,length = data
ascii_list[index][:length] = [ord(char) for char in name]
# length list of each batch then sort and get sorted imdex
seqlen_list,index = torch.sort(torch.Tensor(seqlen_list),descending=True)
countries_code = countries_code[index].long()
ascii_list = torch.LongTensor(ascii_list)
ascii_list = ascii_list[index] # (batch * s)
ascii_list = ascii_list.T # ( s * batch )
return useGPU(ascii_list), useGPU(countries_code), seqlen_list
-
-
-
模型代码:
-
embed
- 输入shape(seq,batchsize)
- 输出shape(seq,batchsize,hiddensize)
-
pack
- 输入shape(seq,batchsize,hiddensize)
- 输出shape(seq * batchsize - blanked,hiddensize)
-
gru
- 输入shape(seq,batchsize,hidden_size)
- 输出
- output:(seq,batchsize,hidden_size)
- hn:(num_layers * bidirectional,batchsize,hidden_size)
-
Lineaner:
- 输入shape:(batchsize,hidden_size * bidirectional)
- 输出shape(batchsize,num_classes)
-
class GRUModule(nn.Module): def __init__(self,input_size,hidden_size,num_layers,batch_size,num_countries,biredirection:bool = True) -> None: super().__init__() self.input_size = input_size self.hidden_size = hidden_size self.num_layers = num_layers self.batch_size = batch_size if biredirection: self.num_hidden = 2 else: self.num_hidden = 1 self.embeded = nn.Embedding(num_embeddings=self.input_size,embedding_dim=self.hidden_size) self.gru = nn.GRU(input_size=self.hidden_size,hidden_size=self.hidden_size,num_layers=self.num_layers,bidirectional=biredirection) self.fc = nn.Linear(in_features=hidden_size*self.num_hidden,out_features=num_countries) # if bidirection=true,need to cat all the hn on hidden_size dim def forward(self,input,seqlen): # input = s, batch batch_size = input.size(1) h0 = self.init_hidden(batch_size) embed = self.embeded(input) # s * batch * hidden input_pack = rnn.pack_padded_sequence(input=embed,lengths=seqlen) # (s * batch - blank,hidden) #hn = (num_layers,batch,hidden) out,hn = self.gru(input_pack,h0) if self.num_hidden == 1: fc_input = hn[-1] else: fc_input = torch.cat((hn[-1],hn[-2]),dim=1) fc_out = self.fc(fc_input) # batch * num_class return fc_out def init_hidden(self,batch_size): h_0 = torch.zeros(self.num_layers*self.num_hidden,batch_size,self.hidden_size) h_0 = useGPU(h_0) return h_0
- 训练:
- ```python
num_country = len(train_data.country_list)
gruclassifier = GRUModule(input_size=INPUT_SIZE,hidden_size=HIDDEN_SIZE,num_layers=NUM_LAYERS,batch_size=BATCH_SIZE,num_countries=num_country,biredirection=BIDIRECTION)
if USE_GPU:
gruclassifier = gruclassifier.to(device=device)
lossfunc = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(gruclassifier.parameters(),lr=LR)
def train(epoch):
total_loss = 0
for data in trainloader:
input,labels,seqlenlist = make_tensors(data_loader=data)
optimizer.zero_grad()
out = gruclassifier(input,seqlenlist) # batch , num_class
loss = lossfunc(out,labels)
total_loss = total_loss + loss.item() # labels = batch
loss.backward()
optimizer.step()
if(epoch % 10 == 9):
print('[ epoch = {} ] , loss = {}'.format(epoch,total_loss))
return total_loss
-
-
test:
-
m_accu = 0 def test(epoch): with torch.no_grad(): accu = 0 total = test_data.len for data in testloader: input,labels,seqlenlist = make_tensors(data_loader=data) output = gruclassifier(input,seqlenlist) _,pred = torch.max(output,dim=1) accu = accu + (pred == labels).sum().item() if(accu / total > m_accu): for data1 in test_setloader: input1,labels1,seqlenlist1 = make_tensors(data_loader=data1) output1 = gruclassifier(input1,seqlenlist1) _,pred1 = torch.max(output1,dim=1) print(pred1.tolist()) print(coun_dit) print('======================================================') for names_ascii_list,index in zip(input1.T.tolist(),pred1.tolist()): name = "".join(chr(char) for char in names_ascii_list) print("name = {} , country = {} ".format(name,coun_dit[index])) print('======================================================') print('[ ============ epoch = {} , accu = {}% ============ \n'.format(epoch,100 * (accu / total))) return accu / total def period(start:float,end:float): all_time = end - start mins = all_time // 60 seconds = all_time - mins * 60 print('USE GPU = {}'.format(USE_GPU)) print('[ during training and testing model , uses {} mins : {} seconds'.format(mins,seconds))
-
- 微信
- 支付宝